Die Networked Computer Science Technical Report Library, kurz NCSTRL ist eine verteilte Bibliothek zur Verwaltung von technischen Reports von Universitäten und Forschungseinrichtungen der Informatik. NCSTRL entstand in der Absicht, Dokumente von verschiedenen Forschungseinrichtungen in einheitlicher Form zu verwalten und gegenseitig zugänglich zu machen. Als Medium des Austauschs bot sich das Internet an. Zwar gab es schon früher einen Austausch von wissenschaftlichen Dokumenten über das Internet, jedoch war der kleinste gemeinsame Nenner entweder ein Austausch via Email oder ein FTP-Server in jeder Einrichtung, von dem die Dokumente abgerufen werden konnten. Selbstverständlich erlaubten diese Lösungen weder eine Suche nach Inhalten noch ein komfortables Handling der Dokumente.
Drei Systeme, auf denen NCSTRL aufbaut gingen wesentliche Schritte in Richtung einer verteilten elektronischen Bibliothek:
 gilt als Pioniersystem auf dem Gebiet der verteilten Verwaltung
Technischer Reporte [16]. Es verbesserte die Nutzbarkeit von
FTP-Archiven dadurch, daß auf einem Server die Indizes aller angebundenen
Archive gespiegelt, verbunden und durchsuchbar gemacht wurden.
Für den Systemadministrator des jeweiligen
Archivs bedeutete das keine Mehrarbeit, da UCSTRI die Indexdateien selbsttätig
kopierte. Allerdings fehlte noch ein einheitliches Dokumentenformat,
so daß das Inhaltsverzeichnis in relativ unstrukturierten
Textdateien geführt wurde (oft die ``README''-Datei des jeweiligen Servers).
Natürlich lieferten dadurch viele Suchanfragen unpräzise Ergebnisse.
(siehe [10]) baute auf UCSTRI auf und brachte ein einheitliches
Dateiformat für die Katalogisierung ein. Außerdem gehörte zu diesem System
ein Tool techrep, das es dem Administrator erlaubte, die Katalogisate
zu erzeugen und auf dem neuesten Stand zu halten.
gilt als Pioniersystem auf dem Gebiet der verteilten Verwaltung
Technischer Reporte [16]. Es verbesserte die Nutzbarkeit von
FTP-Archiven dadurch, daß auf einem Server die Indizes aller angebundenen
Archive gespiegelt, verbunden und durchsuchbar gemacht wurden.
Für den Systemadministrator des jeweiligen
Archivs bedeutete das keine Mehrarbeit, da UCSTRI die Indexdateien selbsttätig
kopierte. Allerdings fehlte noch ein einheitliches Dokumentenformat,
so daß das Inhaltsverzeichnis in relativ unstrukturierten
Textdateien geführt wurde (oft die ``README''-Datei des jeweiligen Servers).
Natürlich lieferten dadurch viele Suchanfragen unpräzise Ergebnisse.
(siehe [10]) baute auf UCSTRI auf und brachte ein einheitliches
Dateiformat für die Katalogisierung ein. Außerdem gehörte zu diesem System
ein Tool techrep, das es dem Administrator erlaubte, die Katalogisate
zu erzeugen und auf dem neuesten Stand zu halten.
Das dritte System, das NCSTRL zugrunde liegt ist das
Dienst-
Protokoll[9].
Dienst wurde als Teil des von der ARPA begründeten
CS-TR-Projekts[3],
an dem fünf Universitäten beteiligt waren (Berkeley, Cornell, CMU, MIT, Stanford).
Das Projekt hatte zwei Ziele:
Grundlagenforschung auf dem Gebiet der elektronischen Bibliotheken zu betreiben und
Methoden zu entwickeln, die es erlauben, Forschungsberichte im Internet verfügbar zu machen.
Als Antwort auf das zweite Ziel wurde die Dienst-Architektur entwickelt, die die vorangegangen
Systeme auf drei Wegen verbessert:
Die Dienst-Architektur bestimmt vier Arten von Services für eine elektronische Bibliothek:
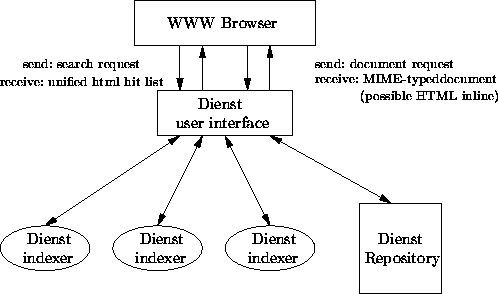
Abbildung 2 zeigt, wie die Servicetypen zusammenarbeiten. Der Anwender verwendet die Benutzerschnittstelle, um seine Suchanfrage dem System mitzuteilen. Eine Suchanfrage besteht aus Schlüsselworten bezogen auf bestimmte Dokumentteile (Titel, Abstract), die evtl. mit logischen Operatoren kombiniert sind. Die Benutzerschnittstelle sendet eine parallele Anfrage an die Index- Server aller Herausgeber.Jeder der Server liefert eine Menge von zur Anfrage passenden docid's, die die Benutzerschnittstelle formatiert und als eine Liste von Hypertext- Links auf die Dokumente anzeigt.
Dienst unterstützt ein Message Passing Interface zur Architektur des Systems. Eine Nachricht kann zu einem einzelnen Server, zu einem Dokument oder zu einem Teil eines Dokuments gesendet werden.
Nachrichten zwischen den Servern werden in der aktuellen Version des Dienst-Systems als URLs codiert und mit dem HTTP-Protokoll gesendet. Die Schnittstelle eines Servers zum Nachrichtenaustausch ist das Common Gateway Interface (CGI), ein Protokoll, daß festlegt, wie ein Web-Server Anfragen an Hintergrundprogramme übergibt und deren Ausgaben an den jeweiligen Client zurückliefert.
Im Falle des Dienst-Systems bearbeitet ein spezieller Daemon alle Anfragen an das System.
Die Syntax eines Dienst-Befehls lautet wie folgt:
http://<Domain>/Dienst/<Service>/<Version>/<Befehl>[/<Parameter>]
Domain kennzeichnet den Domain-Name des Dienst-Servers, z.B.
www.informatik.uni-leipzig.de, Service kann einer der genannten Servicetypen
Repository, Index, UI oder Meta sein,
Version benennt die Version des folgenden Befehls, und Befehl bezeichnet
den eigentlichen Befehl, z.B. SearchBoolean oder List-Contents.
Parameter können z.B. Suchbegriffe oder Formatangaben für das gewünschte Dokument sein.
(Vor jeder Anfrage muß die URL des jeweiligen Web-Servers stehen, z.B.
http://www.informatik.uni-leipzig.de/)
,
Das Dokumentenmodell (siehe Bild 3) der Dienst- Architektur ermöglicht das Speichern eines Dokuments in verschiedenen Formaten. Es ist möglich, eine Liste für ein Dokument verfügbarer Formate anzufordern bzw. das Dokument in einem ganz bestimmten Format zu erhalten.
Ein Dokument, das in die Dienst- Kollektion aufgenommen werden soll, muß entweder in einem gescannten Format vorliegen (z.B. als TIFF- Dateien) oder in einem maschinenlesbaren Format (z.B. als Postscript). Oft werden dann von einem Dokument weitere Formate erzeugt, z.B. eine ASCII- Version (des Abstracts) zur Volltextsuche oder eine Liste von Miniaturbildern der einzelnen Seiten zum schnellen Online- Blättern.
Alle bisher beschriebenen Systeme (UCSTRI, WATERS und Dienst) brachten die Idee einer verteilten Bibliothek ein Stück voran; keinem dieser Systeme war ein erwähnenswerter Einsatz in der Praxis beschert. Das lag daran, daß diese Systeme Forschungsprojekte waren und keine völlige Praxisreife erreichten aber auch daran, daß eine breite Unterstützung von außerhalb der Forschungsgruppen fehlte.
Die Betreiber von NCSTRL gingen von Beginn an einen anderen Weg. Im Hintergrund steht eine Organisation von über 140 nordamerikanischen Informatikfakultäten, Forschungseinrichtungen der Industrie und anderen Vereinigungen.Weiterhin gibt es einen Forschungs- und Entwicklungsplan, der mit der nationalen Forschung auf dem Gebiet der elektronischen Bibliotheken koordiniert ist.
NCSTRL baut, wie bereits beschrieben, auf der Dienst- Architektur auf und verbessert diese in verschiedenen Gesichtspunkten:
NCRSTL benutzt nicht das System der docids des Dienst- Systems. Dafür gibt es zwei Gründe. Als erstes ist der flache Namensraum des Dienst- Systems zu nennen. Zur Erinnerung: Jede docid besteht aus einem Herausgebernamen und einem lokal eindeutigen Dokumentenbezeichner. Damit ist es nicht möglich, den Namensraum hierarchisch zu gliedern. Hinzu kommt, daß die docids systemintern aufgelöst werden, was verhindert, daß auf das Dienst- System von außerhalb zugegriffen werden kann. Damit ist es zugleich unmöglich, das System in ein größeres System zu integrieren.
Stattdessen benutzt NCSTRL das Handle- System zum Benennen von Dokumenten. Das Handle- System wurde von der Corporation for National Research Initiatives (CNRI) entwickelt [4]. Ziel des Systems ist die eindeutige Benennung von Internet- Ressourcen. Bisher werden Ressourcen im Internet durch den Ort ihrer physischen Präsenz identifiziert. Ein Beispiel bilden die Unified Ressource Locators (URLs) des World Wide Web. Der Hauptnachteile einer solchen ortsabhängigen Bezeichnung liegt auf der Hand: Wenn sich der Ort einer Ressource ändert, müssen sämtliche Verweise darauf geändert werden, im WWW ein alltägliches Ärgernis. Handles hingegen gehören zu einem Objekt, nicht zu einem Ort. Das Auflösen eines Handles in die zugehörige Ressourcen- Adresse geschieht durch den globalen Handleserver des CNRI oder einen oder mehrere lokale Server bestimmter Nutzervereinigungen (z.B. alle Unis in Deutschland). Ändert sich der Ort einer Ressource, genügt die Änderung der Adresse im Handle, was vollkommen transparent für den Nutzer der Ressource bleibt.
Abbildung 4 zeigt den Aufbau eines Beispielhandles. Ähnlich wie eine docid besteht ein Handle aus zwei Komponenten, der naming authority und einer beliebigen Zeichenkette. Die naming authority entspricht in etwa dem Herausgeber beim Dienst- System, bietet aber die Möglichkeit der hierarchischen Gliederung im Gegensatz zum flachen Namensraum des Dienst- Systems. Zu jeder naming authority gibt es mindestens einen Administrator, der u.a. das Recht hat, weitere sub-naming authorities zu bilden (und sie in einem lokalen Handle-Server zu verwalten). So wäre es z.B. möglich, unter der naming authority global.loc.de weitere sub-authorities für jede Uni in Deutschland anzuschließen.
Abbildung 5 zeigt das Prinzip.
Leider nutzt das NCSTRL- System die Möglichkeiten des hierarchischen Namensraums aus Gründen der Abwärtskompatibilität nicht. Ein Vorschlag, diesen Nachteil zu beheben, wird in Abschnitt 5.2 besprochen.
Die Idee der Backup- Server entstand aus der Beobachtung heraus, daß bei einer Suchanfrage in der Praxis stets ein gewisser Prozentsatz der Server nicht erreichbar ist. Dafür können viele Gründe in Frage kommen, Hardwarefehler, Überlastung des Servers oder des Netzwerks oder ganz einfach ein Prozeß, der nach einem Reboot nicht neu gestartet wurde.
NCSTRL bietet daher jedem Herausgeber die Möglichkeit, einen oder mehrere Backup- Server anzugeben, die von Zeit zu Zeit den Index des primären Servers spiegeln. Erhalten mehrere Anfragen in Folge keine Antwort, wird der betreffende Server für eine gewisse Zeit als ``down'' markiert. Diese Lösung spart die Zeit, die ein Client auf das Timeout des Servers warten müßte.
Das nicht alle Institutionen die Ressourcen oder das Knowhow besitzen, die relativ umfangreiche Standard- Version des NCSTRL- Systems zu betreiben, entschieden sich die Autoren von NCSTRL, eine funktional abgerüstete Variante des Systems anzubieten, genannt NCSTRL lite. Diese Variante lehnt sich stark an das schon genannte WATERS- Projekt an, das Dokumente eines einheitlichen Formats, die sich auf verschiedenen FTP- Servern befinden können, mit einem zentralen Index verbindet.
Der zentrale Index- Server holt von Zeit zu Zeit die bibliographischen Einträge der zugehörigen Lite- Server und indiziert diese. Dieser zentrale Server wiederum kommuniziert mit anderen Server über das Dienst- Protokoll. Abbildung 6 illustriert dies.
Ob sich ein Dokument auf einem Standard- oder einem Lite- Server befindet, ist für den Anwender vollkommen transparent. Die Suchergebnisse werden ihm immer als Links auf die zugehörigen Dokumente präsentiert.
NCSTRL versteht sich als offenes System mit wohldefiniertem Konzept und Entwicklungsplan. So gibt es Erweiterungspläne der Entwickler selbst wie auch Verbesserungs- und Erweiterungsvorschläge von Forschern außerhalb der Projektgruppe.
Folgende Verbesserungen und Erweiterungen planen die Entwickler von NCSTRL[11]:
Stephan Rücker von der Uni Hamburg schlägt eine Erweiterung des Namensraums des NCSTRL- und Dienst- Systems vor [13]. Die Motivation seines Ansatzes ist in folgenden Unzulänglichkeiten der Systeme begründet:
Rücker schlägt vor, für jedes Dokument mehrere logische Namensbäume zu errichten. So könnte ein Namensbaum die geografische Zuordnung eines Dokumentes repräsentieren, ein anderer eine Zuordnung nach Sachgebieten. Jedes Dokument besitzt ein Home-Handle. Dieses Handle beinhaltet die Metadaten des Dokuments (u.a. dessen Adresse). Alle anderen zugeordneten Handles zeigen auf das Home-Handle, ähnlich wie Links im Unix-Dateisystem. Damit ist es möglich, ein Dokument unter mehreren logischen Namen zu erreichen.

Abbildung 7: Zuordnung des Namenspfades
ncstl.org.sci.cs.world.de.uni-leipzig.de.ifi in den Handle-Baum.
Abbildung 7 zeigt die Zuordnung eines logischen Pfades zu einem Handle-Baum.
Ein Pfad im Namensbaum besteht aus einer logisch sinnvollen Aneinanderreihung von Knotennamen. Ergänzt wird der Pfad durch den Namen eines im bisherigen Pfad schon aufgetretenen Knotens (Syntaktisch gekennzeichnet z.B. durch ein führendes ``-''). Dieser Postfix wird Contributor genannt und regelt die Sichtbarkeit eines Dokuments im Namensraum. Beispiel: Ein Dokument mit dem Handle ncstrl.world.de.hs.uni-leipzig.ifi.-hs/report9702 ist nur im Teilbaum sichtbar, der mit ncstrl.world.de.hs beginnt, also nur innerhalb aller Hochschulen Deutschlands. Der Besitzer des Dokuments wird durch den Knoten gekennzeichnet, der unmittelbar vor dem Contributor steht, im Beispiel ifi.

Abbildung 8: Sichtbarkeit von Dokumenten im erweiterten Dienst-Namensraum.
Abbildung 8 verdeutlicht die Sichtbarkeit von Dokumenten im Namensraum in Abhängigkeit vom zugeordneten Contributor.
Das NCSTRL-System in seiner bisherigen Version ermöglicht nur das Verwalten von Technischen Reporten eines bestimmten Fachgebiets. Eine Unterteilung in Fachgebiete ist weder im Protokoll noch im Datenformat von NCSTRL vorgesehen. Das vorgegebene Datenformat verhindert auch die Integration anderer Dokumententypen.
Von der NASA kommt ein Erweiterungsvorschlag, der es ermöglichen soll, auch Literatur anderer Fachgebiete in NCSTRL zu verwalten. Daneben wird eine Erweiterung auf zusammengesetzte Dokumente beliebigen Typs angestrebt, etwa Dateien oder Programme [11].
Cluster sind logische Teilkollektionen einer elektronischen Bibliothek. NCSTRL unterstützt nur eine Art von Clusterung, nämlich die Aufteilung in Teilkollektionen, die jeweils zu einer bestimmten Naming Authority gehören. Vorgeschlagen wird, das System auf drei Cluster zu erweitern: Organisation (z.B. Cornell University, Uni Leipzig), Kategorie des Dokuments (z.B. Architektur, Informatik) und Genre (z.B. Report, Zeitungsartikel).
Abbildung 9 zeigt einen Beispielbaum des Kategorieclusters.
Um Cluster zu ermöglichen muß lediglich das Dienst Protokoll geeignet erweitert werden. Beispielsweise schlagen die Autoren von NCSTRL+ ein Argument Subject=<Subjecttyp> für die Dienst-Befehle List-Contents und SearchBoolean vor, mit dem spezifiziert wird, welcher Kategorie ein angefordertes Dokument entstammen soll.
Beispielsweise ermittelt die Suchanfrage
Dienst/Index/SearchBoolean?subject=CS&author=rahm&title=datenbank
nur Dokumente der Kategorie ``Computer Science''.
Unter Buckets verstehen die Autoren von NCSTRL+ einen logischen ``Behälter'' zum Erzeugen, Aufbewahren und Anzeigen von Einträgen elektronischer Bibliotheken. Ein Bucket kann verschiedene Packages beinhalten. Eine Package beschreibt die Semantik von Daten, die der Bucket beherbergt, z.B. Manuskripte, Software aber auch Metadaten für den gesamten Bucket, Zeiger auf andere Buckets etc. Jede Package kann aus verschiedenen Elements bestehen. Ein Element beschreibt die Syntax eines Datums und steht meist für die verschiedenen Dateiformate (z.B. HTML, Postscript, TIFF), in denen ein Dokument in der Datenbank gespeichert ist. Ein Bucket definiert Methoden, die den Zugriff auf die Daten regeln oder die Darstellung übernehmen. Die Vorstellungen der Autoren gehen soweit, daß ein Bucket selbst dann nichts von seiner Funktionalität verliert, wenn aus der Datenbank entfernt wird. Abbildung 10 zeigt eine typische Bucket- Architektur.
Von der NCSTRL+ Architektur existieren Prototypen, die schon die nötigen Tools zum Einbringen und Retrieval von Buckets enthalten. Momentan arbeiten die Autoren an einer kompletten Implementation des Systems.