Inhalt:
1.2 Anforderungen
an einen E- Katalog
1.3 Realisierung
von E-Kataloge
1.3.2.1 Architektur von Smart Catalogs
1.3.3.1 Problem mit virtuellen Katalogen
1.3.3.2 Lösung für das Problem
1.3.3.3 Architektur von Virtuellen Katalogen
1.4.1. Für die Verwendung im
Internet
2.3.2. Die Funktionen eines
Mediators
2.4.1. Architektur eines Wrappers
2.4.2. Ziel für die Architektur
dieses Wrappers:
2.4.3. Aufbau eines Garlic Wrappers
2.4.3.1 Modellieren der Daten als Objekte
2.4.3.2 Funktionen bereitstellen und aufrufen
2.4.3.4 Ausführung der Anfrage
3.1 Electronic
Data Interchange - EDI
3.1.1. Zur Funktionsweise von EDI
3.2 Extensible
Markup Language - XML
0. Einleitung
Elektronische Kataloge gewinnen immer mehr an Bedeutung. Informationen im World Wide Web bereitzustellen ist heutzutage ein wichtiger Punkt in der Produktpolitik von Unternehmen. Nicht nur Produkte werden in Katalogen dargestellt auch Dienstleistungen kann man in solchen Katalogen beschreiben. Die elektronischen Kataloge lösen immer mehr die gedruckten Kataloge ab.
In dieser Arbeit wird auf elektronische Kataloge eingegangen, die Vor- und Nachteile diskutiert und auf einige Ansätze speziell eingegangen.
Ein zu betrachtender Punkt ist die Datenintegration. In den meisten Fällen muss ein solcher Katalog, aus von verschiedenen Quellen stammenden Informationen, zusammen gesetzt werden. Hierbei entstehen verschiedene Probleme. Zum einen unterscheiden sich die Quellen in der Struktur; das reicht von einer reinen HTML-Seite über eine Datenbank bis hin zu einem EDI- System. Zum anderen unterscheiden sie sich in der Semantik.
Im zweiten Teil wird auf
Datenintegrationsmethoden eingegangen, insbesondere auf Mediation und Wrapper.
Auch werden Probleme der semantischen Heterogenität und der Schemaintegration
angesprochen.
Im letzten Teil stehen Austauschformate im Mittelpunkt. Sie sind von Bedeutung, um Daten zwischen Unternehmen oder verschiedenen Bereichen in einem Unternehmen auszutauschen und automatisch zu verarbeiten. Auch kann man mit solchen Austauschformaten Kataloginformationen schnell zwischen den gewünschten Partnern austauschen. Hier wird auf EDI und XML eingegangen.
1. Kataloge und
E-Kataloge
Das
Medium, auf dem die heutigen Kataloge erscheinen variiert sehr stark, wobei die
gedruckte Version von Katalogen, auf Papier, immer mehr von der digitalen
Version auf CD oder im Internet abgelöst wird. Dies hat viele Vorteile und
bringt auch einige Schwierigkeiten der Datenintegration und Performance mit
sich, auf die im nächsten Abschnitt eingegangen wird.
Definition
nach [AD98]: E-Kataloge sind jegliche Art von graphischen Userinterfaces
(typisch in HTML), welche Informationen über Produkte oder
Servicedienstleistungen bereitstellen.
Wie zum
Beispiel:
-
Produktbeschreibungen im
Internet
-
Onlineshopsysteme
-
Support im Internet
(Hilfesysteme bei Problemen)
-
Bereitstellung von
Informationen im Internet ( ProQuest)
|
|
Elektronische
Kataloge |
Gedruckte
Kataloge |
|
Aktualität |
Up to date |
Fix auf ein Datum |
|
Updatemöglichkeit |
Einfach und schnell. |
Neudruck |
|
Verteilung |
Internet, Intranet, Extranet, Versand |
Versand |
|
Informationsgehalt |
Beliebig viel |
Beschränkt |
|
Art
der Darstellung |
Individuell |
Einheitlich |
|
Produktsuche |
Indexsuche vielfältige Suchfunktionen |
Index Inhaltsverzeichnis |
|
Weitere
Vorteile |
„Hypertextfähigkeit“ |
Benutzer kann Bemerkungen direkt im Katalog machen |
Tabelle 1: Vergleich von elektronischen mit gedruckten Katalogen
Elektronische
Kataloge haben den gedruckten Katalogen gegenüber verschiedene Vorteile. Diese
sind in Tabelle 1 aufgelistet. Ein elektronischer Katalog der direkt beim
Hersteller installiert ist und über eine Netzwerkverbindung für andere
zugänglich ist, kann zu jeder Zeit einfach und schnell vom Katalogbetreiber
aktualisiert werden. Dagegen muss bei dem gedruckten Katalog dieser komplett
neu gedruckt und verteilt werden.
Um die
Kataloge an den Kunden weiterzugeben gibt es beim gedruckten Katalog nur den
Versand. Auch ein elektronischer Katalog auf CD zum Beispiel kann per Post an
den Kunden gesendet werden. Eine schnelle und kostengünstige Möglichkeit der
Verteilung eines elektronischen Kataloges besteht in der Nutzung des Internets.
Im
weiteren wird von elektronischen Katalogen gesprochen die online verfügbar
sind, weil diese Vorteile gegenüber den offline Katalogen bringen. Bei
elektronischen Katalogen kann man speziellere und tiefere Informationen mit
einbinden und diese durch Einstellungen und Links verfügbar machen. Bei den
gedruckten Katalogen dagegen muss man genau abwägen, welche Informationen
hinein kommen sollen. Damit niemand zu wenig Informationen bekommt und andere
nicht überladen werden.
Mit der
Präsentation der Informationen verhält es sich ähnlich, diese kann man bei
digitalen Katalogen genau an den
jeweiligen Benutzer anpassen, z.B. Abfrage des gewünschten Modus (Standard,
Profi).
Die
Suchfunktion ist eine der wichtigsten Vorteile von elektronischen Katalogen,
wobei man den gedruckten Katalogen nur im Inhaltsverzeichnis und im Index
durchsuchen kann. Ist es bei elektronischen Katalogen möglich dies über alle
Informationen, die im System sind auszuweiten. So zum Beispiel nach gewissen
Eigenschaften suchen. Sucht jemand bei einem Textilhersteller einen schwarzen
Anzug in der Größe 48, in einem gedruckten Katalog kann jener nur im
Inhaltsverzeichnis nach Anzügen suchen und muss dann alle Anzüge sukzessive
durchsuchen, wobei man bei einem elektronischen Katalog die Anfrage stellt und
alle schwarzen Anzüge in der Größe 48 bekommt. In einem gedruckten Telefonbuch
kann man nur zu einem Namen die Telefonnummer suchen umgekehrt ist dies sehr
schwierig, dagegen in der digitalen Version kein Problem.
1.1 Einordnung von Katalogen

Abbildung 1: Einordnung von Katalogen
Wie in Abbildung 1 gezeigt können Kataloge als erstes in elektronische und gedruckte Kataloge unterteilt werden. Diese Unterteilung erfolgt an dem Medium, an das der Katalog gebunden ist.
Die elektronischen Kataloge lassen sich in offline und online Kataloge unterteilen. Wobei mit offline die elektronischen Kataloge gemeint sind, die nach dem Veröffentlichen nicht mehr geändert werden können, wie zum Beispiel Produktkataloge auf CD oder anderen festen Medien. Die online Kataloge dagegen unterliegen ständigen Änderungen, diese können während des Betriebes erfolgen. So entsteht eine den Anforderungen gerechte Aktualität der Kataloge.
Diese online Kataloge werden weiter in stand-alone-Kataloge und virtuelle Kataloge unterteilt, wobei stand-alone-Kataloge nur auf die Informationen eines Anbieters aufbauen, zum Beispiel der Produktkatalog von einem Hersteller. Virtuelle Kataloge dagegen beinhalten Informationen aus verschiedenen Quellen, wie zum Beispiel wenn ein Einzelhändler die Produkte seiner Lieferanten in einem Katalog zusammen darstellt.
Eine Sammlung mehrerer Kataloge, also ein Katalog von Katalogen wird shopping mall genannt. Hierbei werden die einzelnen Kataloge, in der shopping mall, nur erwähnt und sind von ihr aus verlinkt. Eingebettete Kataloge sind dagegen Kataloge die Daten von anderen Katalogen im eigenem „look and feel“ darstellen. Und somit nach außen wie ein smart Catalog erscheinen.
1.2 Anforderungen an einen E- Katalog
Anforderungen
an einen E-Katalog nach [AD98] und [KG96]:
-
Interaktivität: Es soll möglich sein, gezielte Anfragen an das System zu
stellen und vom System die relevanten Antworten zu bekommen. Einstellungen, die
vom Benutzer am System gemacht werden, sollen überall gelten und in jeder
Anfrage berücksichtigt werden (Design, Filter- und Suchkriterien).
-
Up-to-date: Die Informationen, welche in diesem System stehen, sollten
immer auf dem neuesten Stand sein. Das System soll Möglichkeiten des updaten
enthalten und zwar auf eine Weise, dass nicht die kompletten Daten erneuert
werden müssen, sondern nur die
entsprechenden Teile. Ein E-Katalog kann nicht offline gebracht werden, um ein
Update durchzuführen.
-
„Hypertextfähigkeit“:
Es soll möglich sein Produkte oder Informationen miteinander zu verlinken,
um somit schnell zwischen den Produkten/ Informationen zu navigieren.
-
Globale Präsenz: Durch das Internet ist es möglich, wenn erwünscht, den
E-Katalog dem ganzen Internet zur Verfügung zu stellen, um so ein viel größeres
Publikum zu erreichen.
-
Heterogenität: Bei größeren Katalogen oder bei Katalogsammlungen wird es
immer wieder nötig, Informationen anzubieten, die aus unterschiedlichen Quellen
kommen und somit auch das Datenformat dieser unterschiedlich ist. Ein E-Katalog
muss nun Möglichkeiten bieten, solche heterogenen Daten analysieren, damit
umgehen und in einem einheitlichen Format darstellen zu können.
-
Offene Architektur: Ein E-Katalog muss ständig erweitert werden. Das Wachstum
im Internet verläuft so schnell, dass
heute niemand sagen kann, welche Informationen in welcher Art in einem
E-Katalog stehen müssen. Dieser sollte demnach so aufgebaut sein, dass er
jederzeit für neue Systeme, Datenformate und Informationsquellen offen und
erweiterbar ist.
-
Suchtechniken: Es ist sehr wichtig die richtigen Informationen in angemessener
Zeit zu finden. Ein E-Katalog sollte verschiedene Möglichkeiten der Suche
anbieten, wie zum Beispiel die Suche nach Namen, Gruppen oder Eigenschaften von
Produkten. Weiter sollte es eine Volltextsuche in den Produktbeschreibungen
geben, welche über alle dem Katalog zugrundeliegenden Informationsquellen erfolgen
sollte (cross-search).
1.3 Realisierung von E-Kataloge
Im folgenden werden EDI- Kataloge, Smart Catalogs und virtuelle Kataloge beschrieben, wobei Vor- und Nachteile dieser diskutiert werden.
1.3.1. EDI- Kataloge
EDI- Kataloge basieren auf dem EDI 832 Transaktions Standard. Diese Kataloge sind über ein value-added network (VAN) verfügbar. Benötigt jemand Informationen aus einem solchen EDI- Katalog so benutzt er EDI 832 tansactions und speichert die Daten lokal.
Als Vorteil für EDI- Kataloge ist der genau definierte Standard zu nennen, es bedarf keiner Absprache zwischen den Unternehmen, um Informationen auszutauschen. Dieser Standard birgt aber viele Nachteile in sich, wie die Unflexibilität bei neuen anderen Daten; so ist die Produktinformation bei EDI auf Codes, Nummern und eine kurze Textbeschreibung beschränkt. Es ist nicht möglich beispielsweise an Stelle des Farbcodes den Namen der Farbe zu speichern, wie einige Industriezweige es sich wünschen. Der EDI 832 Standard unterstützt keine Bilder, Videos und andere Dateiformate die von Unternehmen zu Unternehmen unterschiedlich gespeichert werden, auch kann die Produktbeschreibung nur bis zu 20 Zeichen enthalten.
1.3.2.
Smart Catalog
Smart
Catalog sind Kataloge, die nur von einer bestimmten Firma bereitgestellt werden
und nur die Daten dieser Firma beinhalten. Hauptziel dieser Kataloge ist es
nach [KG96] eine effektive Suchfunktion zu implementieren, die es ermöglicht,
auch beim Bilden von virtuellen Katalogen, die Suchmechanismen über alle einzelnen
Smart Catalogs auf eine effektive Art zu nutzen. Ein weiteres Ziel ist es die
Kataloge auch für Partner zugänglich zu machen, für die diese primär nicht
bestimmt waren und jetzt aus Kostengründen zugänglich gemacht werden können.
1.3.2.1 Architektur von Smart
Catalogs
Dem Smart
Catalog liegt eine Datenbank mit Produktinformationen zugrunde. Diese befinden
sich am gleichen Ort, so dass es keine Probleme mit der Anbindung gibt.
Innerhalb der gleichen Unternehmen wird in der Regel das gleiche Vokabular
verwendet und die Struktur der Datenbank ist wohl bekannt.

Abbildung 2: Smart Katalog
Wie in Abbildung 2 gezeigt greift der Smart Katalog mit Hilfe des Katalog Agents auf die Daten zu. Der Catalog Agent ist die Hauptkomponente des Smart Catalogs. Er ist genau an die Art der zugrundeliegenden Daten angepasst. Diese können in Form einer Datenbank, Text Dateien oder Web-Seiten vorliegen. Der Catalog Agent stellt Funktionen zur Verfügung, um auf die Daten zuzugreifen. Auch unterstützt er verschiedene Schnittstellen nach außen. Der Smart Catalog kann mehrere Schnittstellen zur Clientanwendung unterstützen; hier wird der Katalog als HTML-Seite an einen Web Client gesendet und zusätzlich über ein EDI Client zugänglich gemacht.
1.3.3.
Virtuelle Kataloge
In
vielen Fällen müssen Kataloge gebildet werden, deren Inhalt nicht aus dem
eigenen Unternehmen, sondern als Sammelung verschiedener Daten von
verschiedenen Quellen bestehen. In dieser Arbeit wird das
Hersteller-Händler-Konsumenten Szenario als Beispiel genommen, um die
auftretenden Probleme zu erläutern. Wobei ein Händler mehrere Hersteller als
Lieferanten hat und dessen Produktinformationen für den Kunden aufbereiten
muss.
1.3.3.1 Problem mit virtuellen
Katalogen
Jeder
Hersteller hat seinen Smart Catalog und der Händler hat mehrere Hersteller mit
verschiedenen Smart Catalogs. Da jeder Smart Catalog anders ist, von der Art
Webbasiert, EDI, usw. und von dem zugrundeliegenden Schema, stellt diese
Integration aller Smart Katalogs in einem Katalog ein Problem dar. Um alle diese
Daten in einen eigenen Katalog zu importieren und zu speichern, ist der Aufwand
meist zu hoch. Nicht allein das Einfügen, sondern die ständige Aktualisierung
ist schwierig.
1.3.3.2 Lösung für das Problem
-
„verlinkter virtueller
Katalog“: Nun kann der Händler seinen
virtuellen Katalog durch Links mit den Seiten des Herstellers verbinden, um
seinen Kunden die Möglichkeit zu geben, in den Produkten nach speziellen Daten/
Details zu suchen. Dabei existieren mehrere Probleme: 1. der Kunde „get lost“,
er weiß nicht, wie er auf die Seite des Händlers zurückkommen kann. 2. der
Hersteller weiß nicht was der Kunde des Händlers sucht oder welche Erwartungen
er hat. 3. der Kunde des Händlers stolpert über eine Bestellmöglichkeit des
Herstellers oder eines Dritten. 4. der Kunde findet den Weg zurück zu dem
Händler, z.B. mit Hilfe des „Back“ Buttons, dabei gehen aber alle
Konfigurationen die er am Produkt des Herstellers gemacht hat verloren. 5.
gelangt der Kunde zurück zu dem Händler, hat der Händler keine Informationen
über die Interaktionen mit dem Hersteller (ob der Kunde vielleicht schon ein Bestellformular
beim Hersteller ausgefüllt hat und nun eine Doppelbestellung aufgegeben hat).
-
„virtueller Katalog“: Eine weitere Möglichkeit wäre, wenn der Hersteller
Möglichkeiten unterstützt, mit Hilfe derer der Händler automatisch
Produktinformationen auf eine spezielle Anfrage bekommen kann. So ist der
Händler in der Lage einen Katalog aufzubauen, der sich die Daten bei Bedarf von
dem Herstellerkatalog holt und in einem eigenen virtuellen Katalog darstellt.
Der virtuelle Katalog setzt eine Zusammenarbeit des Herstellers mit dem Händler
voraus.
Der
Kunde stellt eine Anfrage an den virtuellen Katalog des Händlers und dieser
übersetzt jene automatisch für die Herstellerkataloge und stellt diese Anfrage
in Echtzeit an die Kataloge aller in Frage kommenden Hersteller. Die Antworten
werden dynamisch zusammengesetzt und an den Client zurückgegeben.
Vorteile:
-
Der Katalog des Händlers ist
immer auf dem neuesten Stand.
-
Der Händler kann entscheiden
welche Daten er von dem Hersteller einbinden will, ob alle oder nur einen Teil
der Produkte der einzelnen Hersteller.
-
Die Interaktion des Kunden
mit dem Virtuellen Katalog ist komplett unter der Kontrolle des Händlers, die Informationen des Herstellers sind auf
Abruf ehrhaltbar und der Kunde hat die gesamte Zeit über das „look and feel“
des Händlers.
1.3.3.3 Architektur von Virtuellen
Katalogen
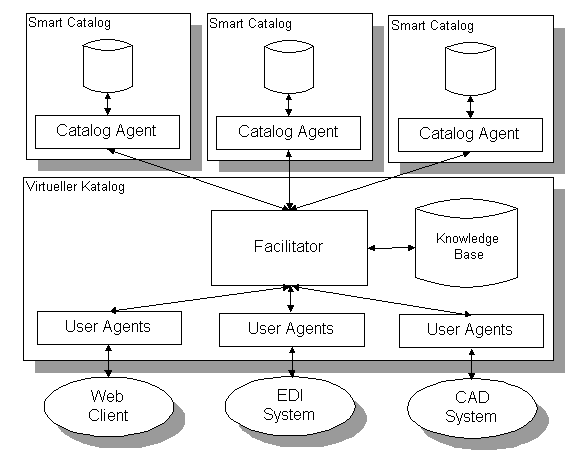
Abbildung 3:Virtueller Katalog
Der Client (Web, EDI oder anderer) stellt eine Anfrage an das System, speziell an den für ihn zuständigen User Agent. Dieser übersetzt diese in die interne Agent Communication Language (ACL) und sendet diese weiter an den Facilitator. Der Facilitator weiß mit Hilfe seiner Knowledge Base, welche Catalog Agents er fragen muss, um die gewünschten Antworten zu bekommen. Er fungiert als ein Broker. Er übersetzt die Anfragen in die Syntax der in Frage kommenden Catalog Agents und sendet diese zu den jeweiligen. Die Knowledge Base wird im Vorfeld beim Entstehen des virtuellen Kataloges aufgebaut und kann im Laufe der Zeit immer wieder erweitert werden. Dabei gibt jeder Catalog Agent bekannt, welche Anfragen über welches Thema er beantworten kann. Weiter wird in der Knowledge Base die Ontologie der jeweiligen Catalog Agents gespeichrt, um eine Übersetzung in diese zu ermöglichen. Der Catalog Agent erfüllt drei Aufgaben: 1. gibt er den Inhalt der zugrundeliegenden Datenbank bekannt 2. versteht er Anfragen vom Facilitator und übersetzt diese in eine Sprache, welche die Produktdatenbank versteht 3. nimmt er die Antworten von der Produktdatenbank entgegen und übersetzt diese in ACL für den Facilitator. Der Catalog Agent ist ein Wrapper, der genau einer Produktdatenquelle zugeordnet ist. Auf Wrapper wird in Abschnitt 2.3. näher eingegangen.
Die
erhaltenen Antworten werden vom Facilitator, der als Mediator fungiert
(Abschnitt 2.2.), analysiert und zusammengesetzt an den Client Agent
zurückgegeben, der diese in die entsprechende Sprache des Clients übersetzt und
diesem übergibt.
1.4 Verfügbare Katalogsysteme
Die
meisten Kataloge die man im Internet findet sind nach dem gleichen Schema
strukturiert. Dadurch kann der Internetnutzer rein intuitiv in den Seiten
navigieren. Oft findet man eine Navigationsleiste, an derer man sich grob
orientieren kann. Es erfolgt eine Auflistung der Produkte in einer Tabelle und
man kann sich dann die Detailbeschreibung im genauen ansehen.
1.4.1. Für die Verwendung im
Internet
In der
folgenden Tabelle wird einen kurzen
Überblick über einige Anbieter von Katalogsystemen geben.
|
URL |
Produkt |
Preis |
Kommentar
|
|
Krakaloa
Web Catalog |
ab
$1.500 |
Besitzt
eine ojektorientierte Datanbank |
|
|
CenWARE
HTML |
$50.000
für 10.000 Einträge |
Inkl.
Beratungsservice |
|
|
Curtis Catalog |
Standard $1.795 Professional $2.495 |
|
|
|
Dataware E-Catalog |
ab $15.000 |
Inkl. Support |
|
|
Elkom
Procurement |
$25.000
für 50 Nutzer |
Intergiert
ODBC Datenbanken |
|
|
Electronic Commerce Suit iCat
Publisher |
Standard
$3.496 Professional
$9.995 |
Inkl.
Design- und Management-Tools |
|
|
CatSmart |
ab
$9.995 |
Das
Paket beinhaltet einen Smart System Manager, Consumer-Driven Shopper,
enterprise Integrator und eine Business Partner Gateway |
|
|
Step Search Enterprise |
ab
$20.000 |
Läuft
unter Unix, NT Version ist geplant |
Tabelle 2: Produktübersicht über die Anbieter von Katalogsystemen
1.4.2. www.iSport.de
 Als Beispiel eines eingebetteten Shopsystems möchte ich ein
von uns selbst entwickeltes vorstellen. Es geht darum, verschiedene Sportshops
in einem Shopsystem darzustellen. Um auf allen Seiten und in allen Shops immer
das gleiche Design und Navigation zu realisieren haben wir uns für ein
eingebettetes Shopsystem entschieden. Dies schafft Vertrauen beim Kunden, weil
er auf jeder Seite und in jedem Shop das gleiche Design vorfindet. Das Konzept
ist ähnlich dem des zShops von Amazon, nur liegt unser Hauptaufmerksamkeit auf
einer einfach intuitiv bedienbaren Oberfläche, sehr hohe Spezialisierung durch
Spezialshops und wenn erwünscht sehr genaue Informationen zu den Produkten und
eine breite Produktpalette.
Als Beispiel eines eingebetteten Shopsystems möchte ich ein
von uns selbst entwickeltes vorstellen. Es geht darum, verschiedene Sportshops
in einem Shopsystem darzustellen. Um auf allen Seiten und in allen Shops immer
das gleiche Design und Navigation zu realisieren haben wir uns für ein
eingebettetes Shopsystem entschieden. Dies schafft Vertrauen beim Kunden, weil
er auf jeder Seite und in jedem Shop das gleiche Design vorfindet. Das Konzept
ist ähnlich dem des zShops von Amazon, nur liegt unser Hauptaufmerksamkeit auf
einer einfach intuitiv bedienbaren Oberfläche, sehr hohe Spezialisierung durch
Spezialshops und wenn erwünscht sehr genaue Informationen zu den Produkten und
eine breite Produktpalette.
Dieses System basiert auf einer Microsoft Lösung. Zugrunde liegt eine SQL- Datenbank, die über ODBC wie in Abbildung 5 gezeigt, angesteuert wird. Zur Zeit ist dies noch eine MS Access Datei, die aber jederzeit ohne Aufwand durch eine SQL- Server ersetz werden kann. Die HTML-Seiten werden auf dem Microsoft Internet Information Server 4.0 mit Hilfe von ASP erzeugt. Die Schnittstelle zwischen ASP und dem ODBC bildet ADO. Die gesamten Seiten werden je nach Bedarf zusammengestellt und an den Webbrowser gesendet.
|
Abbildung 5: Datenzugriff |
Abbildung 6: Datenbankzugriff vom Katalog |

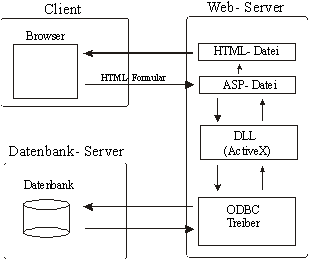
Die Erzeugung der Katalogseiten erfolgt mit Hilfe von ASP. Wie in Abbildung 6 gezeigt wird ein HTML-Formular an den Web-Server gesendet. Dieses Formular muss nicht wie ein gewöhnliches Formular mit Eingabefeldern auftreten, sondern kann in diesem Fall auch ein Link mit Parametern sein, wie es in diesem Shopsystem vorkommt. Die Daten werden von einer ASP- Datei entgegengenommen und verarbeitet. Diese ASP- Datei ruft die gewünschten ADO’s mit den Datenbankanfragen auf und wandelt die Ergebnisse in eine HTML- Datei um, die dann an den Client gesendet wird.
2. Datenintegrationsmethoden
Bei dem
Zusammenfügen von Information verschiedener Quellen, wie dies bei virtuellen
Katalogen geschieht, gibt es
unterschiedliche Probleme. Zum einen ist die Struktur der Datenquellen
unterschiedlich, dies reicht von einfachen Textdateien über Webseiten bis hin
zu verteilten Datenbanken. Zum zweiten weicht das Datenbankschema voneinander
ab. Es muss eine Möglichkeit gefunden werden auf alle diese unterschiedlichen
Quellen mit der gleichen Effizienz und auf die verschiedenen zugrundeliegenden
Strukturen einheitlich zuzugreifen.
2.1 Semantische Heterogenität
Die auftretenden Konflikte können nach [Ra94] in Schemakonflikte und Datenkonflikte unterteilt werden. Wobei Schemakonflikten in Namenskonflikte, strukturelle Konflikte und Konflikte bei Integrationsbedingungen unterscheiden und die Datenkonflikte in unterschiedliche Datenrepräsentation und fehlende/ widersprüchliche Datenbankinhalte unterteilen kann.
- Namenskonflikte: Es gibt zwei Arten von Namenskonflikten: die Synonyme und die Homonyme. Wobei bei Synonymen zwei identische Objekte in unterschiedlichen Quellen unterschiedliche Namen haben. Wie zum Beispiel „CPU Speed“ bei Hersteller A und „CPU Takt“ bei Hersteller B, bedeuten die Inhalte das Gleiche, nämlich die Taktfrequenz in MHz. Die Homonyme sind Objekte, die zwar bei verschiedenen Quellen den gleichen Namen tragen, aber unterschiedliche Inhalte darstellen.
- Strukturelle Konflikte: Strukturelle Konflikte treten auf, weil die Struktur der Daten unterschiedlich ist. Sie treten in vielfältiger Weise auf. So können semantisch gleiche Informationen in unterschiedlicher Weise gespeichert werden.
- Konflikte bezüglich Integritätsbedingungen: Diese beziehen sich auf die Relationsebene, unterschiedliche Definition der Primärschlüssel, unterschiedliche Definition zur Wartung der referentiellen Integrität, unterschiedliche Definitionsbereiche der Attribute, Default Werte, Nullwerte usw.
- Datenpräsents: Hierbei handelt es sich um Konflikte, die bei gleichem Schema auftreten, wenn die zugrundeliegenden Daten von unterschiedlichen Definitionen ausgehen. Wenn beispielsweise die Angabe von Preisen in unterschiedlichen Währungen erfolgt.
- Fehlende/ widersprüchliche Daten: Tritt durch Eingabefehler oder falschen Grunddaten auf.
2.2 Schemaintegration
Nach [Ra94] ist das Ziel der Schemaintegration, aus den in den verschiedenen Quellen existierenden Schemata ein globales Gesamtschemata zu entwickeln. Es soll möglich sein, auf alle Quellen gleichzeitig zuzugreifen mit nur einem bekannten Schema. Der Prozess der Schemaintegration ist zum größten Teil nicht automatisch durchführbar und muss manuell durchgeführt werden.
Es existieren verschiedene Strategien zur Schemaintegration. In [Ra94] werden zwei Ansätze gegenübergestellt. Diese unterscheiden sich darin, ob zwei oder mehr Schemata in einem Schritt zusammengeführt werden. Bei der Integration von mehr als zwei Schemata kann versucht werden alle Schemata in einem Schritt zu integrieren (one-shot). Oder mehrere Schemata in einem Schritt zu integrieren und mehrere aufeinander folgende Schritte durchführen (iterativ). Die binäre Strategie verfolgt den Ansatz, genau zwei Schemata zu integrieren. Dabei kann man linear oder balanciert vorgehen.
Die Schemaintegration unterteilt sich in folgenden drei Phasen:
-
Vorintegration: Hier wird die zu verwendende
Strategie und die Reihenfolge festgelegt. Es wird versucht, Abhängigkeiten zwischen
den verschiedenen Schemata zu finden. Weiterhin werden Transformationsfunktionen
gebildet, die potentiell äquivalente Wertebereiche aufeinander abbildet. Mit
solchen Funktionen kann eine Umwandlung der Datentypen (numerisch, nicht
numerisch) oder die Vereinheitlichung von Preisangaben erfolgen.
- Konflikterkennung und – behandlung: Probleme der semantischen Heterogenität müssen erkannt und behoben werden. Bei Namenskonflikten wird eine Umbenennung durchgeführt. Die Erkennung von Homonymen ist leicht und automatisierbar. Dagegen kann die Behandlung struktureller Konflikte sowie von Konflikten hinsichtlich Integritätsbedingung nicht automatisiert werden. Dies muss manuell geschehen.
-
Mischen und Rekonstruieren: Dieser Schritt ist
nicht automatisierbar. Hier werden die Informationen der verschiedenen Schemata
so zusammengefügt, dass keine Informationen verloren gehen. Es soll weiter
minimal und leicht verständlich sein.
2.3 Mediation
Nach
[Wg94] werden sogenannte Mediators als Vermittler zwischen der Datenquelle und
der Anwendungsschicht eingesetzt, welche die Daten der unterschiedlichen Quellen
aufnehmen und in einer einheitlichen Weise darstellen/ weitergeben. In [Wg94]
wird ein Weg gezeigt, um benutzerrelevante Informationen in verschiedenen
Quellen zu finden und nach Wichtigkeit sortiert wiederzugeben bzw. zu
speichern.
2.3.1. Architektur

Abbildung 7: Eine Vermittler Architektur
Die horizontale Unterteilung erfolgt in drei Ebenen: den Client Anwendungen, den Vermittlungsservice und den Datenservern.
Die vertikale Unterteilung erfolgt in Domains. Die Mediatoren werden so geschrieben, dass diese auf eine Domaine von Datenquellen spezialisiert sind. Zum Beispiel gibt es einen Mediator für Wetter der auf Quellen, die Wetterinformationen enthalten, spezialisiert ist. Diese Speziealisation erlaubt eine genauere Behandlung der Informationsquellen vom Mediator. Wenn eine Anfrage über verschiedene Domains gestellt wird und es werden mehrere Mediatoren benötigt, muss die Zusammensetzung der entsprechenden Antworten in der Endanwendung erfolgen und wenn nötig mit Einflussnahme des Anwenders.
Die drei horizontalen Ebenen:
-
Datenserver: Die Selektierung der Daten sollte am Server selbst
erfolgen, um nicht unnötig viele Daten zu dem Client oder Mediator zu schicken.
Die beste Möglichkeit auf eine Datenquelle zuzugreifen, ist der Zugriff mittels
dem SELECT statement von SQL. Nicht viele der Datenquellen (vor allem im Internet)
unterstützen dies. Eine Lösung wäre der Einsatz von sogenannten Wrappern auf
oder in der Nähe des Servers, worauf im nächsten Abschnitt eingegangen wird.
-
Cient: Interaktion mit dem Nutzer ist eine wichtige Eigenschaft
von den Clientprogrammen. Lokale Antworten müssen schnell und zuverlässig
erscheinen.
-
Mediator: Es ist weder auf dem Server noch auf dem Client möglich
Funktionen bereitzustellen, mit denen die Daten von den Servern zu Informationen
zusammengefasst werden können. Es kann nicht jeder Server die Funktionalität
besitzen, um jedes Clientprogramm zu bedienen. Umgekehrt ist es nicht möglich
oder vernünftig, jedes Clientprogramm mit Funktionen auszustatten, um auf jeden
Server zuzugreifen, darum wurde in [Wg99] eine Schicht dazwischen eingeführt,
der Mediator. Er stellt Funktionen zur Verfügung, die im nächsten Abschnitt
behandelt.
2.3.2.
Die Funktionen
eines Mediators
- Fokussierter Zugriff auf verschiedene Quellen: Ein
Mediator befragt mehrere Quellen. Dabei muss es möglich sein bei jeder
Quelle den Fokus auf das Wesentliche zu lenken. Zum Beispiel, wenn man
Produktinformationen über ein bestimmtes Produkt auf verschiedenen Quellen
sucht, sollen nur die relevanten Produkte im Fokus des Mediators stehen.
- Selektieren von relevantem Quellmaterial [Sa90]
und ordnen: Der Mediator soll in der Lage sein, relevante Informationen
von den irrelevanten zu unterscheiden. Die gefundenen Informationen sind
von unterschiedlicher Detailtiefe, diese muss erkannt und sortiert werden.
- Zusammenfügen der Informationen von
verschiedenen Quellen: Ein Mediator
befragt mehrere Quellen, dabei kommt es zu Redundanzen, Fehlern in den
Daten und unnötig viele Details. Nun besteht die Aufgabe des Mediators
darin die Informationen aus den verschiedenen Quellen richtig zusammenzufügen.
Der Mediator kann Regeln enthalten, z.B. Quelle A ist immer besser als
Quelle B, neuere Daten sind immer besser. Weiter müssen Verknüpfungspunkte
gefunden werden. Diese sind in Ausdrücken oder Beziehungen zu suchen. Ist
die Ontologie der Quellen unterschiedlich werden ontological tools
verwendet, um diese einheitlich zu gestallten.
- Umwandlung des Materials in eine für den
Benutzer verständliche Form: Auch nach dem Auffinden der Informationen,
Analysieren des relevanten Teils und Zusammenfügen dieser, müssen jene
noch in eine für den Benutzer verständliche Form gebracht werden.
- Anpassung an die Verbindungsbandbreite und
Multimediafähigkeit des Endbenutzers: Weiterhin muss die Antwort vom
Mediator auch auf die technischen Bedingungen des Benutzers angepasst werden.
Wenn der Benutzer an einem Textterminal sitzt nützt es ihm nichts, wenn
der Mediator ganze Bilder oder Videos zu ihm überträgt, oder wenn er nur
mit einer dail-up Verbindung mit dem Mediator verbunden ist, muss der
Mediator das erkennen und die Daten dafür aufarbeiten.
2.3.3. Ontology
Eines der größten Probleme für den Mediator ist der Umgang mit den verschiedenen Ontologien. Ein Attributname kann in einem anderen Zusammenhang etwas anderes bedeuten. Für jede Domaine muss eine Ontologie definiert werden, die das Vokabular und die Beziehungen in dieser Domaine genau beschreibt.
Eine Möglichkeit besteht darin alle vorkommenden Begriffe zu nehmen und einem Komitee zu geben. Dieses Komitee muss nun eine gemeinsame Ontologie finden, die für alle akzeptabel ist. Ist diese definiert, so muss jedes Dokument in die Ontologie übersetzt werden.
Als weitere Möglichkeit gibt es das Bilden einer Wissensbasis. In dieser werden Regeln der übereinstimmenden Begriffe gespeichert, In [Wg94] wird folgendes Beispiel angegeben:
S: Domaine S sind Schuhläden, mit den Objekten, Schuhe, Kunden, Verkäufer, Geschäftslage und Lieferanten.
F: Domaine F sind die Schuhhersteller, mit den produzierten Schuhen, Material der Schuhe, Materiallieferanten, Angestellte und Produktionsanlagen.
Es ist nicht möglich beide Ontologien komplett überein zu bringen, weil man leicht sieht, dass in der einen Domaine zum Teil andere Daten, als in der anderen stehen. Die entstandenen Regeln in der Wissensbasis sehen wie folgt aus:
S:supplier.name = F.factory.name
S:shoe.zize = F.shoe.size
S:shoe.color = color_table (F:shoe.color)
Die Farbtabelle beinhaltet die Übersetzung der Farbcodes des Herstellers in den Namen der Farbe für den Verkäufer. So das z.B. bei dem Hersteller 13XF3 steht und das das gleiche wie pretty pink bei dem Verkäufer bedeutet.
2.4 Wrapper
Zu
einer weiteren Möglichkeit verschiedene Datenquellen zu integrieren zählt die
Wrappertechnologie.
Der
Wrapper sitzt direkt an der Datenquelle. Er ist in der Lage alle Daten aus ihr
zu generieren und weiterzugeben. Auch ermöglicht er Funktionen, welche die
Datenquelle nicht erfüllt, auf ihr auszuführen. Beispielsweise, wenn diese
keine Suchfunktionen erlaubt, fragt der Wrapper alle relevanten Daten ab und
führ eine Suche über diese aus.
Der
Wrapper bildet die Schnittstelle zu den unterschiedlichen Datenquellen. Daraus
folgt, dass der Wrapper auf jede Datenquelle extra angepasst werden muss, um
mit dieser zusammen arbeiten zu können. Jede Datenquelle hat ihr eigenes
Schema, Programmierinterface und
Anfragesprachen. Das Datenmodell kann relational oder objektorientiert sein,
das Schema kann feststehen oder über den Verlauf der Zeit variieren und manche
Datenquellen unterstützen eine Anfragesprache wie SQL, andere haben ihren
eigenen Dialekt oder manche erlauben nur eine Volltextsuche über die
zugrundeliegenden Dateien. Dies zeigt, dass die Architektur der einzelnen
Wrapper sich sehr stark unterscheidet.
2.4.1. Architektur eines Wrappers

Abbildung 8: Garlic Architektur
Die
Abbildung 8 zeigt den groben Aufbau eines solchen Wrapper- Systems. Jeder
Datenquelle ist ein Wrapper zugeordnet. Die Metadata stellt eine Komponente
dar, in der das zusammengefasste Schema gespeichert wird. Das Herzstück des
Systems ist der Query Processor, dieser teilt die einzelnen Anfragen in
effiziente Teile für jede Datenquelle auf, so das jede Datenquelle die bestmögliche
Antwort geben kann.
2.4.2. Ziel für die Architektur dieses Wrappers:
-
Die Einführungskosten eines
Wrappers sollen so gering wie möglich sein.
Das Schreiben eines Wrappers setzt das Wissen über die Struktur der
zugrundeliegenden Daten voraus. Um das Schreiben eines solchen Wrappers so
einfach wie nur möglich zu gestalten, werden nur eine geringe Zahl von
Funktionen vom Wrapper erwartet.
-
Wrapper müssen
weiterentwickelbar sein. In [KS98] wird
mit einem Wrapper begonnen, der die zugrundeliegenden Dateninhalte als ein
Garlicobjekt darstellt. Dieser wird im Laufe der Zeit bei Bedarf erweitert, so
dass er Anfragesprachen oder Funktionen der Datenquelle unterstützt.
-
Die Gesamtarchitektur muss
flexibel sein und ein Wachstum erlauben.
So muss es möglich sein, neue Wrapper hinzuzufügen, ohne das Garlic- System zu
verändern, Garlic- Anwendungen zu beeinflussen oder gar andere Wrapper zu
manipulieren.
-
Die Architektur sollte von
sich aus die Anfragen an die einzelnen Datenquellen optimieren. Da bei einer Anfrage eines Clients an das System diese
Anfrage nicht für alle Datenquellen optimiert werden kann, übernehmen die
Wrapper selbstständig die Optimierung
der Anfragen.
2.4.3. Aufbau eines Garlic Wrappers

Abbildung 9: Funktionen eines Wrappers
In Abbildung 9 werden die vier Hauptfunktionen eines Wrappers in einem Garlic System gezeigt. Diese werden im Folgenden dargestellt.
2.4.3.1 Modellieren der Daten als
Objekte
Der
Wrapper stellt die Daten der zugrundeliegenden Quelle in ein Garlic Objekt dar.
Dabei hat jedes Garlic Objekt ein Interface, welches die Objekteigenschaften
beschreibt. Während der Registrierung einer Datenquelle beschreibt der Wrapper
den Inhalt dieser in der Garlic Data Languages (GDL). Die Quelle wird als Teil
der Garlic Datenbank registriert und das Einzelschema der Daten wird in einem
Gesamtschema des Garlicsystems dargestellt und dem Benutzer präsentiert.
Als
Beispiel wird das in [Wg94] erwähnte genutzt. Hier wird ein Reisebüro
beschrieben, welches ein Garlicsystem benutzt. Dieses Reisebüro speichert
Informationen über Länder und Städte in einer Agentur internen relationalen
Datenbank. Außerdem hat das Reisebüro Zugriff zu Buchungssystemen für Hotels
und zu einem image Server, der die Bilder der angebotenen Hotels liefern kann.
Die folgende Abbildung 10 zeigt das entsprechende Schema.
|
|
|
|
|



Abbildung
10: Travel Agency Application Schema
2.4.3.2 Funktionen bereitstellen und
aufrufen
Die
zweite Aufgabe des Wrappers ist es, Funktionen auf die Objekte bereitzustellen.
Es gibt zwei Arten von Funktionen, einmal die fest definierten, wie matches()
und zum anderen gibt es zu jedem Attribut eine „set“ und eine „get“ Funtkion.
Das Garlic- System oder eine Garlic- Anwendung kann Funktionen aufrufen und der
Wrapper gibt diese an die Datenquelle weiter. Falls die Quelle die Funktionen
nicht unterstützt, muss der Wrapper diese so umwandeln, dass sie ausgeführt
werden kann.
2.4.3.3 Planung der Anfrage
Der
Wrapper unterstützt den Query Processor beim Planen einer Anfrage. Nach [RS98]
besteht das Hauptziel in der Entwicklung von Alternativanfragen und in der
Auswahl der Effizientesten.
Der
Garlic Optimizer teilt die Gesammtanfrage für jede Datenquelle auf und sendet
diese zu den entsprechenden Wrappern. Diese Wrapper senden null oder mehr
Möglichkeiten dieser gesamten oder nur einen
Teil Anfrage an das Garlic- System zurück. Der Garlic Optimizer bildet
nun eine Menge von möglichen Anfragen, die aus den einzelnen Antworten der
Wrapper zusammengesetzt wird. Der Wrapper wird bei der Query Planung benötigt,
weil jede Datenquelle bestimmte Restriktionen besitzt, wie die maximale Anzahl
von Joins, die maximale Query Länge oder den Maximalwert einer Variablen.
Weiter ist der Wrapper in der Lage die Einschränkungen in der Query zu
kompensieren und zusätzliche Such- und Zugriffsmethoden zu bieten, wenn diese
nicht von der Datenbank unterstützt werden.
-
Access Plans: Der Garlic Optimizer bekommt eine SQL- Anfrage und
übersetzt diese in ein Work Request für den Wrapper, dieser Work Request
enthält alle relevanten Variablen, Bedingungen und Methoden der SQL- Anfrage.
Der Wrapper schaut nun, welchen Teil er bearbeiten kann und sendet einen Access
Plan, mit den von ihm zu beantwortenden Teil, an den Garlic Optimizer zurück.
In diesem Beispiel (Abbildung 11) soll der Wrapper die SQL- Anweisung
bearbeiten. Es wird ein Hotel gesucht, welches 5 Sterne hat und am Strand
liegt. Der Wrapper erhält diesen Work Request und stellt fest, dass er alles
behandeln kann außer die Lage am Strand, die er in dem entsprechenden Access
Plan weg läst. Jetzt weiß der Garlic Optimizer, welchen Teil der Anfrage dieser
Wrapper bearbeiten kann.
-
Join Plans: Sind in der Anfrage Joins enthalten, die über Tabellen
einer Datenquelle gehen, so wird der Wrapper gebeten, eine Query zurückzugeben,
die diesen Join in der Datenquelle ausführt. Dies geschieht wieder mit einem
Work Request an den Wrapper, der dann mit einem Join Plan antwortet. In
Abbildung 12 wird das anhand eines Beispiels gezeigt. Hier befinden sich die
zwei Tabellen Countries und Cities in einer Datenquelle und der Wrapper soll
diese Abfrage über zwei Tabellen mittels eines Joins verbinden. Das Ergebnis
ist der entstandene Join Plan.
-
Bind Plans: Unterstützt die zugrundeliegende Datenquelle Variablen, so
ist es möglich, mit einem weiteren Work Request an den Wrapper diese in die
Anfrage aufzunehmen. In Abbildung 13 wird gezeigt wie der Name der Stadt als
Variable in die Abfrage eingebunden wird.
2.4.3.4 Ausführung der Anfrage
Die
letzte wichtige Aufgabe des Wrappers besteht in der Ausführung der Anfrage an
die zugrundeliegenden Daten.
Die entstandene Anfrage setzt sich aus mehreren Teilen zusammen, die sich als Baumstruktur darstellen lässt und nacheinander abgearbeitet werden. So wird in Abbildung 14 gezeigt, wie die Abfrage ausgeführt wird. Es sollen alle 5 Sterne Hotels gefunden werden, die in Griechenland, in einer kleinen Stadt und am Strand liegen. Als erstes wird ein Web Wrapper mir einer Abfrage gestartet über den Ort, also welche Hotels mit 5 Sternen in den Daten stehen. Da diese Datenquelle kein „like“- Prädikat unterstützt, führt der Wrapper einen Filter aus, der nach dem Begriff „beach“ in der Ortbeschreibung sucht. Als drittes wird diese Abfrage mit einem Joint an die relationale Wrapper Anfrage gebunden, wobei als Joinbedingung der Hotelname genommen wird. Der relationale Wrapper soll einen Bind Plan zurückgeben, der über die Tabellen Countries, Cities und Hotels geht. Am Ende werden der Hotelname und der Tagespreis ausgegeben.
|
Abbildung 11: Access Plans
Abbildung 13: Bind Plans |
Abbildung 12: Join Plans
Abbildung
14: Query Executing |




3. Datenaustauschformate
Seit
Beginn der Bearbeitung von Geschäftsprozessen auf elektronischem Weg besteht
das Bedürfnis, diese Daten zwischen Anwendungen auszutauschen. Diese
Anwendungen können innerhalb eines Rechners, eines Unternehmensnetzwerkes oder
zwischen verschiedenen Unternehmen sein. Dabei ist es von Bedeutung, einen Standard
zu entwickeln, der es allen Anwendungen erlaubt, die Daten auf elektronischem
Weg effizient und kostengünstig verteilen und verarbeiten zu können. Der
Standard sollte so beschaffen sein, dass es möglich ist ohne Erweiterung dieses
neue Anwendungen zu integrieren. Hier haben sich einige Standards durchgesetzt,
wobei die Diskussion nach besseren und kostengünstigeren, immer wieder aufgegriffen
wird.
Als
erstes wird in diesem Abschnitt näher auf EDI eingegangen, welches in den
letzten 30 Jahren am Wichtigsten und unter größeren Unternehmen am
Verbreitesten war und sicherlich auch in Zukunft sein wird.
Als
nächstes wird XML erwähnt, was vor allem beim Einsatz im Internet von Bedeutung
ist. Ein Vergleich der beiden Standards soll diesen Abschnitt abschließen.
3.1 Electronic Data Interchange - EDI
Täglich werden im Geschäftsverkehr große Mengen an Papierdokumenten (Bestellungen, Rechnungen, Lieferscheine, Belege etc.) erstellt, verarbeitet und verschickt. Mit EDI (Elektronic Data Interchange) kann dieser Prozess weitgehend optimiert werden. Denn elektronische Daten können maschinell versendet und verarbeitet werden. Mit EDI steht ein enormes Nutzenpotential zur Verfügung. Viele große und kleine Unternehmen setzen schon seit Jahren erfolgreich auf EDI, um Zeit und Kosten zu sparen.
Unter
EDI als Schlagwort versteht man allgemein den Austausch von strukturierten
Daten auf elektronischem Wege (Electronic Data Interchange).
Zur
Vermeidung einer Vielzahl bilateraler Datenaustauschformate befasst sich die
"Arbeitsgruppe für die Vereinfachung von internationalen
Handelsverfahren" der Vereinten Nationen mit der Entwicklung von normierten
Datenaustauschformaten. Das Ergebnis dieser internationalen Zusammenarbeit
ist der Standard UN/EDIFACT, ein lebendiger Standard, der kontinuierlich den
Marktentwicklungen angepasst wird.
EDIFACT
(Electronic Data Interchange For Administration
Commerce and Transport) bezeichnet also eine standardisierte
Beschreibung der Datenstruktur, die die elektronische Abwicklung vieler geschäftlicher
Vorgänge zwischen Unternehmen, Branchen und Ländern möglich macht; und dieses
hard- und softwareunabhängig. Das bedeutet, dass mittels EDIFACT jeder mit
jedem elektronischen Datenaustausch betreiben kann, ohne Rücksicht auf die
individuell eingesetzten Computersysteme und Geschäftsprozesse.

Abbildung 15: traditionelle und elektronische Art der Datenübermittlung (Quelle: www.dedig.de)
3.1.1.
Zur Funktionsweise
von EDI
Die nach EDIFACT standardisierten
Datensätze werden zwischen EDI-Partnern ausgetauscht. Niemand muss seine
bestehende Soft- und Hardware gegen ein EDIFACT-fähiges System auswechseln! Es
genügt, das bestehende Inhouse-System um eine EDI-Schnittstelle in Verbindung
mit einem Konverter zu erweitern und sich einem VAN-Provider (Netzdienstleister)
anzuschließen. Der Konverter übersetzt Daten vom Inhouse-Format in EDIFACT (und
umgekehrt) und übergibt sie dem VAN. Dieser leitet die Daten an den Empfänger
weiter, der wiederum einen Konverter benutzt, um die EDIFACT-Daten in sein
Inhouse-Format zu übersetzen.
Auf diese Weise kann - egal auf welcher Systemplattform - jeder mit jedem
kommunizieren!
Die
Sinnhaftigkeit der Nutzung von EDI liegt im automatisierten, batchorientierten
Datenaustausch, der sich auch wirtschaftlich niederschlägt (siehe Nutzenpotentiale)
und der Eindeutigkeit der übermittelten Daten, die keinen
Interpretationsspielraum geben.
Dabei muss das Prinzip, soweit wie möglich Standards einzusetzen, verfolgt werden, um keine ineffektiven Punkt-zu-Punkt-Verbindungen zu schaffen.
3.1.2. Vorteile von EDI
Vorteile
nach [KD99] von EDI, die heute noch gelten:
-
Standardisiert: Unternehmen mit einer großen Anzahl von
Datentransaktionen nutzen EDI zur Übertragung dieser zu anderen Unternehmen,
weil das Datenformat konsistent und standardisiert ist.
-
Volumen: EDI erlaubt eine schnelle massenhafte Verarbeitung von
Dokumenten, die Daten können gesammelt und in einem Schub übertragen werden,
dies spart Verbindungskosten.
-
Vertrag: VAN und das Unternehmen haben einen Vertrag. VANs
bestätigen den Versand von Nachrichten/ Dateien, diesen Dienst kann im Internet
niemand anbieten.
-
Support: VANs bieten 24x7 Support. Ist man heute zur „falschen“
Zeit im Internet, hat man mit langsamen Übertragungsraten zu rechnen.
-
Serviceleistungen: VANs bieten verschiedene Serviceleistungen an, um die
Übertragung zu sichern.
-
Kosten: Nach [KD99] sind die Kosten eines solchen Systems über das
Internet zu betreiben höher (sicherlich nicht, wenn man nur einen simplen
Browser braucht, aber sobald man größere Transaktionen durchführt und
Bestellungen, Rechnungen, Bestätigungen usw. darüber abwickeln und automatisch
verarbeiten möchte, wird es sehr aufwendig).
3.2 Extensible Markup Language - XML
Nach [W3C98] ist die Extensible Markup Language, abgekürzt XML, eine Beschreibungssprache für XML- Dokumente. Diese XML-Dokumente beschreiben teilweise das Verhalten von Computer-Programmen, die solche Dokumente verarbeiten.
XML-Dokumente sind aus Speicherungseinheiten aufgebaut, genannt Entities, die entweder analysierte (parsed) oder nicht analysierte (unparsed) Daten enthalten. Analysierte Daten bestehen aus Zeichen, von denen einige Zeichendaten und andere Markup darstellen. Markup ist eine Beschreibung der Aufteilung auf Speicherungseinheiten und der logischen Struktur des Dokuments. XML bietet einen Mechanismus an, um Beschränkungen der Aufteilung und logischen Struktur zu formulieren.
Ein Software-Modul, genannt XML- Prozessor, dient dazu, XML- Dokumente zu lesen, und den Zugriff auf ihren Inhalt und ihre Struktur zu erlauben. Es wird angenommen, dass ein XML-Prozessor seine Arbeit als Teil eines anderen Moduls, genannt Anwendung, erledigt. Diese Spezifikation beschreibt das notwendige Verhalten eines XML-Prozessors, soweit es die Frage betrifft, wie er XML-Daten einlesen und welche Informationen er an die Anwendung weiterreichen muss.
3.2.1. XML Beispiel
Hier
ein Beispiel für XML. Es handelt sich um einen Auszug aus einer XML-Datei.
<customer-details id="AcPharm39156">
<name>Acme Pharmaceuticals Co.</name>
<address country="US">
<street>7301 Smokey Boulevard</street>
<city>Smallville</city>
<state>Indiana</state>
<postal>94571</postal>
</address>
</customer-details>
Die XML- Syntax enthält immer Start und End -tags für jeden Wert, wie <name> und </name>. Diese tags können Attribute enthalten wie country="US" bei dem address-tag. Diese Systax erinnert sehr an HTML, nur ist hier die Art der tags sauberer definiert und kann somit von jeder Anwendung eindeutig und einfach verstanden werden.
3.3 XML und EDI
XML steht nicht in Konkurrenz zu EDI. Klassische Austauschverfahren werden vielmehr ergänzt. XML bietet für EDI eine Zahl von Vorteilen. EDI-Nachrichten können als XML- Dokumente dargestellt und mit nicht strukturierten multimedialen Daten ergänzt werden. Mit XML wird der Übergang vom batchorientierten Austausch zur Near- Realtime- Kommunikation möglich. Der Einstieg für Unternehmen mit geringem Transfervolumen in den wirtschaftlichen Datenaustausch ist durch XML nun möglich.
Auf der anderen Seite sind die
Nachteile von EDI: die genaue Definition und die Unflexibilität beim hinzukommen
neuer Datenformate. Hier muss der EDI- Standard jedes Mal erweitert werden.

Abbildung 16: Einsatz des Internets für EDI (Quelle: www.dedig.de)
Wie in
Abbildung 16 gezeigt wird läst sich das Internet in zweifacher Hinsicht
sinnvoll für EDI nutzen.
Zum
einen lässt sich das Internet als kostengünstiges Transportmittel einsetzen,
wobei die EDI- Software davon nicht betroffen ist. Hierfür muss nur der
Kommunikations- Server um ein
internetfähiges Kommunikationsmodul erweitert werden. Der Transport kann
mittels FTP oder eMail erfolgen, wobei für die in der Öffentlichkeit viel
diskutierten Sicherheitsprobleme mittlerweile diverse Sicherheitsprodukte, die
durch Verschlüsselung nicht nur dem Ausspionieren der Daten, sondern ebenso der
Vorspiegelung einer falschen Identität oder dem Datenverlust, vorbeugen.
Als
nächstes lässt sich das Internet nutzen, um transaktionsarme Geschäftspartner
von Großunternehmen auf der Basis von Web-basierten Formularen an das EDI-
System anzubinden, ohne dass diese Kosten für ein EDI-System aufbringen müssen.
Dazu muss der Betreiber eines solchen EDI- Systems Internet Server mit Software
bereitstellen, welche die Umwandlung der EDI- Daten in HTML- Dateien vornehmen.
Dies kann für dieses Unternehmen kostenintensiv sein, aber es erreicht damit
viele kleinere Unternehmen, die im Normalfall nie ein EDI- System genutzt
hätten. Diese benötigen nun nur noch einen Internetzugang und einen Webbrowser.
4. Zusammenfassung
Das
Hauptziel von Online Katalogen ist es den Nutzer schnell, präzise und
vollständig mit den relevanten Informationen zu versorgen. Die technischen
Voraussetzungen sind zum größten Teil geschaffen, nur die Realisierung muss
noch in einer für den Kunden angemessene Form erfolgen, zum Beispiel sind viele
der heutigen Shopsysteme Kundenunfreundlich (Überladene Seiten, schlechte
Übersichtlichkeit, schlechte Navigation).
Das Problem
der Datenintegration bei Katalogen, die sich aus mehreren unterschiedlichen
Quellen zusammensetzen, kann man durch Ansätze wie die der Mediatoren [Wg94]
[Wg99] oder mit Hilfe eines Garlicsystems mit Wrappern [RS98] lösen.
EDI
bietet einen sehr genauen und bei großen Unternehmen akzeptierten Standard, um
Informationen in großen Mengen auf schnelle und effektive Weise auszutauschen,
und automatisch zu verarbeiten. Da sich dieser Standard bei Unternehmen
durchgesetzt hat und Kosteneinsparungen/ Wettbewerbsvorteile bringt, ist es
nicht sinnvoll ihn durch einen neuen Standard zu ersetzten. XML bietet die
Möglichkeit, EDI um wichtige Funktionen zu erweitern und auch für andere
kleinere Unternehmen, für die sich EDI wirtschaftlich nicht gelohnt hat, zum Einsatz
zu bringen. Dadurch werden die Vorteile der beiden Standards kombiniert.
5. Literaturverzeichnis
[AD98] Adam N.R.,
Dogranaci O., Gangopadhyay A., Yesha V.: Electronice Commerce: Technical,
Business and Legal Issues, Pentice Hall, 1998.
[DFKR99] Davulcu,
H.; Freire, J.; Kifer, M.; Ramakrishnan, I.V.: A Layered Architecture for
Querying Dynamic Web Content. SIGMOD '99 Seite 491-502.
[DS98] Danish S.: Building Database-driven Electronic
Catalogs, SIGMOND Record. Vol. 27, No 4, December 1998, Seite 15-20.
[EH97] Ean Houts: Cat@log: Software you can bank on,
Infoworld, Sep 1997.
[KD99] Doris Kilbane: Internet commerce considerations,
Oktober 1999
http://www.proquest.com.
[KG96] Arthur M. Keller, Michael R. Genedereth, Stanford
University, Computer Science Dept.: Multivedor Calalogs: Smart Catalogs and
Virtual Catalogs.
[KG98] Keller,
A.M.; Genesereth, M.R.: Smart Catalogs and Virtual Catalogs. EDI-Forum,
The Journal of Electronic Commerce, Vol. 9, No. 3, Seite 97-93.
[MAMMS98] Mecca,
G.; Atzeni, P.; Merialdo, P.; Masci, A.; Sindoni, G.: From Databases to
Web-Bases: The Ariadne Experience. Technical Report RT-DIA-34-1998,
Universität Rom.
[MB98] Martin Bryan, The SGML Center: Guidelines
for using XML for Electronic Data Interchange, January 1998, http://www.geocities.com/WallStreet/Floor/5815/guide.htm.
[MPZ98] Martin, P.; Powley, W.; Zion, P.: A
Metadata Repository API. 5. KRDB-Workshop '98
http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-10.
[PW97] Watt P.: Catalog designers
cultivate intranets, Intranet, July 1997.
[Ra94] Rahm, E.: Mehrrechner
Datenbanksysteme, Addision Wesley 1994
[RS97] Roth, M.T.; Schwarz, P.: Don't
Scrap It, Wrap It! A Wrapper Architecture for Legacy Data Sources.
Proceedings of 23. VLDB Conference 1997, Seite 266-275.
http://SunSITE.Informatik.RWTH-Aachen.de/dblp/db/conf/vldb/RothS97.html.
[RS98] Roth,
M.T.; Schwarz, P.: A Wrapper Architecure for
Lagacy Data Sources, IBM Almaden Research Center, 1998.
[UW99] Universität
Würzburg: Interactive-EDI,
http://www.wiinf.uni-wuerzburg.de/helios/interactiveedi.htm.
[W3C98] W3C:
Extensible Markup Language (XML) 1.0, Februar
1998
[Wg92] Wiederhold,
G: Intelligent Integration of Diverse Information. Keynote presentation
at CIKM 92, Baltimore MD, 1992
http://www-db.stanford.edu/pub/gio/gio-papers.html.
[Wg94] Gio Wiederhold: Interoperation,
Mediation, and Ontologies, Nov 1994
http://www-db.standford.edu/pub/gio/gio-papers.htm.
[Wg95] Wiederhold,
G.: Digital Library - Value, and Productivity. Communications of the
ACM, 38(4), April 1995, http://www-db.stanford.edu/pub/gio/gio-papers.html.
[Wg99] Wiederhold,
G.: Mediation to Deal with Heterogeneous Data Sources. Interoperating Geographic
Information Systems, Springer LNCS 1580 (Proc. Interop'99, Zurich, 1999), Seite
1-16
http://www-db.stanford.edu/pub/gio/1999/Interopdocfigs.html.