
Problemseminar im SS 1997
Elektronische Bibliotheken
Thema:
SGML und Datenbanken
Bearbeiter : Thomas Nowotka
Betreuer: Dr. D. Sosna
Inhaltsverzeichnis
1 EINLEITUNG
2 SGML
2.1 Logische Struktur eines Dokumentes
2.2 Aufbau eines SGML-Dokumentes
2.3 Syntaxelemente
2.4 Aufbau einer DTD
2.5 SGML und HTML
3 DER HYTIME STANDARD
3.1 Was ist HyTime
3.2 Möglichkeiten mit HyTime
3.3 HyTime-Links
3.3.1 Contextual Link ( clink )
3.3.2 Independent Link ( ilink )
4 SGML UND DATENBANKEN
4.1 Vorteile eines elektronischen Informationssystems
4.2 SGML-Dokumente in einer Datenbank
4.2.1 Objektorientierte Datenbanken
4.2.2 Festlegung der Granularität der
Daten
4.2.3 Beispiel einer praktisch realisierten
SGML-Datenbank
4.2.3.1 Abfragen über Strings
4.2.3.2 Abfragen über Pfaden und Attribute
4.2.4 Probleme bei der automatischen Erzeugung
von Objektklassen aus einer DTD
5 ZUSAMMENFASSUNG
6 LITERATUR
Die Informationsfülle der heutigen Zeit erfordert leistungsfähige
Möglichkeiten Dokumente zu verwalten, zu archivieren und wiederzuverwenden.
Insbesondere dem Punkt der Wieder/Mehrfachverwendbarkeit sollte besondere
Aufmerksamkeit gewidmet werden, da die Erstellung von Dokumenten recht
zeit- und kostenaufwendig ist. Eine Mehrfachverwendung von Dokumenten für
verschiedene Anwendungen ist anzustreben. Neben dem Papier, welches seit
Jahrhunderten als Träger von Informationen dient, kommen heute neue
Technologien und Speichermöglichkeiten zum Einsatz, welche es erlauben
nicht nur Text und Bildinformationen, sondern auch Video-, Audiodaten,
Computersimulationen etc. innerhalb eines Dokumentes abzulegen. Der Zugriff
auf die Informationen eines Dokumentes kann über geeignete Suchmöglichkeiten
vereinfacht und beschleunigt werden. Elektronische Bibliotheken bieten
nicht nur die Möglichkeit der Archivierung von Dokumenten, es ist
auch eine Aktualisierung der Datenbestände möglich. Des weiteren
besteht die Möglichkeit an einem Dokument viele Autoren gleichzeitig
arbeiten zu lassen, z.B.: Lexika, kommentiertes Vorlesungsverzeichnis.
Das Anbieten der Dokumente in Computernetzen ermöglicht dem Benutzer
einen wesentlich schnelleren und umfassenderen Zugriff auf die Informationen.
Für die Nutzung der Daten ( Dokumente ) in Computersystemen werden
geeignete Technologien benötigt, die folgende Eigenschaften aufweisen
sollten:
Beschränkt man sich auf den Inhalt eines Dokumentes, stellt man fest, daß eine Trennung des Dokumentinhaltes von Layoutfragen möglich und sinnvoll ist, sowie einige neue Möglichkeiten eröffnet. Jedes Dokument, wie z.B. Bücher und Zeitschriftenartikel besitzt eine logische Struktur, d.h. man kann unterscheiden zwischen Überschriften, Inhaltsverzeichnis, Abbildungen, "normaler" Text etc. . Erstellt man ein Dokument mit zusätzlicher Auszeichnung der eben genannten Elemente, hat man den gleichen Informationsgehalt wie in einem mit herkömmlichen Mitteln erzeugten Dokument. Die Vorteile des neuen Dokumentes sind:
SGML (Standard Generalized Markup Language) (Standardisierte Verallgemeinerte Auszeichnungssprache) wurde 1986 als internationaler Standard ( ISO 8879:1986 ) verabschiedet. SGML definiert eine Sprache zur logischen Strukturierung von Dokumenten. SGML selbst ist kein Austauschformat für Dokumente. Es ist lediglich ein Mittel, um anwendungsspezifische Dokumentenaustauschformate zu definieren. Sogenannte Dokumenttypdefinitionen (DTD) enthalten die Beschreibung aller in einer bestimmten Klasse von Dokumenttypen zusammengefaßten Dokumente. Die Beschreibung der gewünschten Darstellung wird außerhalb des SGML-Dokumentes vorgenommen. Einigt man sich auf eine DTD, so kann ein Dokumentenaustausch erfolgen. Angewendet wird SGML z.B. für den Dokumentenaustausch zwischen Flugzeugherstellern und Fluglinien. ( Beispiel in [TRWA95] Appendix 3 "Case Study: Douglas Aircraft Company" )
Unter der logischen Struktur eines Dokumentes versteht man eine Beschreibung
einer Zerlegung des Dokumentes in einzelne abgeschlossene Teile, wie z.B.
Überschrift, Absatz oder Abbildung. Hat man ein Dokument logisch strukturiert
in elektronisch verarbeitbarer Form vorliegen, hat man einige Vorteile.
Der Autor kann sich mehr auf die eigentlichen Inhalte seines Dokumentes
konzentrieren, und braucht sich nicht um Layoutfragen zu kümmern.
Eine einheitliche Darstellung des Dokumentes kann ohne größeren
Aufwand erreicht werden. Möchte man z.B. Hervorhebungen mit kursivem
Text darstellen, werden die entsprechenden Stellen im Dokument damit ausgezeichnet
( z.B. <vorheb> ). Das Formatierprogramm setzt dann die Auszeichnung
"<vorheb>" in Kursivschrift um. Für eine Änderung von "kursiv"
nach "fett" muß lediglich in der Übersetzungstabelle des Formatierers
eine Anpassung vorgenommen werden. Bei herkömmlichen Textverarbeitungssystemen
hätte man im schlechtesten Fall alles manuell ändern müssen.
Eventuell vergißt man noch Textstellen, eine einheitliche Darstellung
wäre mit höherem Aufwand verbunden.
Durch Auszeichnung des Dokumentes mit Marken geht gegenüber herkömmlichen
Dokumenten keine Information verloren. Es besteht vielmehr die Möglichkeit
zusätzliche Informationen in das Dokument einzubringen.
Beispiel 2.1 für Auszeichnung eines Textes:
... ... diese Informationen sind in der Datei <path>/etc/passwd</path> enthalten ... ...
gedruckt könnte das dann vielleicht so aussehen:
...
... diese Informationen sind in der Datei "/etc/passwd" enthalten
...
...
Beispiel 2.2 für mißbräuchliche Verwendung von Auszeichnungen ( aus [BAN94]):
<bold>Specific markup</bold>
To get a feeling for what <italic>markup</italic>
is, consider the traditional processing of texts ...
Hier wurden das Layout betreffende Auszeichnungen vorgenommen. Diese Dinge sollten aber dem Formatierer vorbehalten bleiben. In Ausnahmefällen kann aber die Auszeichnung des Layouts sinnvoll sein. ( z.B. "das ist <fett>fett</fett> geschrieben" )
Ein SGML-Dokument besteht im wesentlichen aus zwei Teilen. Einem Vorspann, der unter anderem die sogenannte Dokumenttypdefinition (DTD) enthält und den mit Marken ( Tags ) ausgezeichneten, eigentlichen Text. Eine DTD beschreibt die logische Struktur eines Dokumentes vollständig, wobei das Dokument durch eine Menge von Grammatikregeln beschrieben wird. Vor diesen beiden Teilen steht die SGML-Deklaration, welche unter anderem den verwendeten Zeichensatz definiert. Als Zeichensatz kommt üblicherweise der ASCII-Zeichensatz zum Einsatz. Daher ist die Darstellung in diesem Zeichensatz nicht vorhandener Zeichen nur über einen Umweg möglich. Für Umlaute wird z.B. "ö" statt "ö" usw. benutzt. ( die Konstruktion "&Bezeichner;" kann auch für eigene Ersetzungen benutzt werden ) Da die meisten Applikationen Voreinstellungen für alle Werte der SGML-Deklaration haben ist ihre Angabe nicht notwendig. Eine vollständige SGML-Deklaration befindet sich in [TRWA95]. Oder im WWW: ftp://ftp.ifi.uio.no/pub/SGML/declaration
Abbildung 1: Aufbau eines SGML-Dokumentes, aus [TRWA95]
Kommentare werden in SGML mit "<!--" oder "--" eingeleitet und mit "--" ( zwei Bindestrichen ) abgeschlossen.
Beispiele für gültige Kommentare:
<!-- Kommentar -->
<!------ Kommentar ------>
<!ELEMENT dpunkt -O EMPTY -- Symbol für Punkt -->
Die logischen Einheiten eines Dokumentes werden Elemente genannt. Die Namen der Elemente werden als Marken im Text benutzt, wobei "<marke>" den Beginn und "</marke>" das Ende einer Einheit kennzeichnet. Eine logische Einheit besteht aus einen Namen, welcher laut [SZ95] maximal 8 Zeichen lang sein darf, und einer Beschreibung ihrer Struktur. Diese Struktur kann sich aus anderen Einheiten oder Grundtypen ( Tabelle 1 ) zusammensetzen. Die Reihenfolge der einzelnen Bestandteile der Einheit wird durch spezielle Verbindungssymbole definiert ( Tabelle 2 ). Die Anzahl des Auftretens eines Bestandteils wird durch spezielle Zeichen festgelegt ( Tabelle 3 ).
| Datentyp | Bedeutung | Hinweise |
|
CDATA |
Character data | bis auf Endmarken wird alles als Textinhalt gelesen |
|
RCDATA |
Replaceable character data | wie CDATA, aber: Einheiten werden durch definierten Text ersetzt |
|
#PCDATA |
Parsed character data | Text der vom Parser bearbeitet werden soll |
|
SDATA |
Specific character data | |
|
NDATA |
Non-SGML data | |
|
EMPTY |
No data-empty element | Platzhalter |
|
ANY |
Any type of data | wie #PCDATA, es findet aber keine Kontrolle der Elementausprägung statt ( Benutzung vermeiden ) |
| Notation | Benutzung | SGML Term | Beschreibung |
|
, |
X,Y |
SEQ |
nach X folgt Y |
|
& |
X&Y |
AND |
X und Y in beliebiger Reihenfolge |
|
| |
X|Y |
OR |
X oder Y |
Tabelle 3: Symbole, die die Häufigkeit des Vorkommens eines Elementes beschreiben
| Vorkommen | Symbol |
| genau ein mal (erforderlich) | (none) |
| höchstens einmal |
? |
| beliebig oft |
* |
| mindestens einmal, beliebig oft |
+ |
Es folgen nun Syntaxdiagramme zur Veranschaulichung der Bedeutung der Elemente aus Tabelle 2 und Tabelle 3. Die Diagramme sind an [TRWA95] angelehnt.

Abbildung 2: Sequenz (",")
Ein Kapitel besteht aus einem Namen und einem Paragraphen.
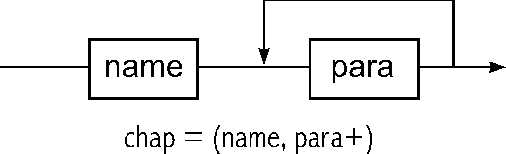
Abbildung 3: "para" tritt mindestens einmal auf ("+")
Der Name des Kapitels wird von einem oder mehreren Paragraphen gefolgt.

Abbildung 4: "para" tritt höchstens einmal auf ("?")
Das Kapitel besteht aus einem Namen und einem optionalen Paragraphen.

Abbildung 5: "para" tritt beliebig oft auf ("*")
Diesmal dürfen beliebig viele Paragraphen auftreten, ein Paragraph muß jedoch nicht auftreten.

Abbildung 6: Alternative ("|")
Nach dem Namen folgt entweder ein Paragraph, oder eine Abbildung.

Abbildung 7: Wiederholung einer Alternative
Nach "name" folgt eine beliebige Menge von Abbildungen und Paragraphen, es muß aber mindestens ein Paragraph oder eine Abbildung auftreten.

Abbildung 8: Zusammensetzung
Beide Notierungen definieren eine gleiche Struktur. Nach dem Namen müssen ein Paragraph und eine Abbildung in beliebiger Reihenfolge erscheinen. In SGML lassen sich also durch geeignete Benutzung der Verbindungssymbole verschiedene Darstellungen für gleiche logische Einheiten erreichen. Welche Deklaration als einfacher verständlich oder übersichtlicher angesehen wird, hängt vom Geschmack des jeweiligen Benutzers ab.
Verarbeitungsanweisungen
Mit Verarbeitungsanweisungen ( processing instructions ) können
Befehle durch den Parser direkt an die Applikation weitergeleitet werden.
Die direkte Weitergabe von Befehlen an die Applikation ist nicht im Sinne
einer standardisierten und systemunabhängigen Dokumentstruktur. Für
spezielle Einsatzgebiete lassen sich damit aber einfachere Lösungen
erreichen. Verarbeitungsanweisungen erlauben die Verwendung systemspezifischer
Kodierungen, welche sonst durch Elemente und Attribute definiert werden
müßten.
Eine Verarbeitungsanweisung hat die Form:
<?Anweisungstext>
Nach "<?" wird alles so lange als Anweisungstext behandelt, bis ">" auftritt. Die Verarbeitungsanweisung darf also kein ">" enthalten.
z.B.: <?page break>
<?CD-ROM JL:Jump, ITIT-CPP-1>
Markierte Abschnitte
Ein markierter Abschnitt ( marked section ) ist ein Textstück, welches durch spezielle Begrenzer eingeschlossen wird, und das vom Parser über spezielle Parameter gesondert behandelt wird. Durch die Parametersteuerung ist es somit insbesondere möglich, Textvarianten zu verwalten. Ein markierter Abschnitt hat die Form:
<![Verarbeitungshinweis(e) [Text]]>
"Verarbeitungshinweis(e)" stehen für Schlüsselworte der Menge
( IGNORE, CDATA, RCDATA, INCLUDE). Mit IGNORE wird der ganze Abschnitt
vom Parser überlesen. Bei INCLUDE wird der Text innerhalb der Begrenzer
normal vom Parser bearbeitet. Durch CDATA wird eine Verarbeitung mit dem
Parser verhindert, der Inhalt wird ohne Parsen weitergereicht. Bei RCDATA
wird eine Ersetzung der Einheiten vorgenommen, die Tags werden jedoch vom
Parser nicht verarbeitet.
"Text" steht für normalen SGML-Text, welcher vom Parser bearbeitet
werden kann.
Beispiel für einen markierten Abschnitt mit Parametersteuerung aus
[COJA96]
<!ENTITY % tex "IGNORE">
Für das TeX-System könnte man folgende Steuerung benutzen, um TeX-Kommandos bedingt zu benutzen.
<![ %tex; [
<!ENTITY newpage "<?\newpage>">
]]>
Eine Dokumenttypdefinition (DTD) beschreibt eine Klasse von Dokumenten und besteht aus der Angabe des Namens dieser Klasse und ihrer Bestandteile. Der Aufbau der DTD ist dabei wie folgt:
"<!DOCTYPE name[]>" definiert eine Klasse "name". Innerhalb der eckigen Klammern werden die Bestandteile dieser Klasse angegeben. Folgende Bestandteile sind möglich:
Tabelle 4: reservierte Bezeichner für Attribute
|
res. Bezeichner |
Bedeutung |
|
#REQUIRED |
Attributwert ist erforderlich. Vorbelegung ist nicht erlaubt |
|
#IMPLIED |
Attributwert ist optional |
|
#CURRENT |
der zuletzt benutzte Wert wird wiederverwendet |
|
#CONREF |
Der Formatierer setzt einen Inhalt ein. Der Attributwert dient dem Formatierer als Verweis auf den einzusetzenden Inhalt. |
|
#FIXED |
fester Wert |
Tabelle 5: reservierte Bezeichner in Attributdeklarationen
| Schlüsselwort | Attributwert |
| CDATA | Character data, allgemeinster Wert |
| ENTITY | Name einer Einheit |
| ENTITIES | Name einer oder mehrerer Einheiten |
| ID | Identifikator, Verankerung eines Verweises, der im Dokument eindeutig sein muß |
| IDREF | Identifikator, Referenzwert |
| IDREFS | Liste von Referenzwerten |
| NAME | Attributwert ist ein gültiger Bezeichner |
| NAMES | Liste von gültigen Bezeichnern |
| NMTOKEN | Zeichenkette, die den Regeln für gültige Bezeichner entspricht |
| NMTOKENS | Liste von NMTOKENS |
| NOTATION | Notation name |
| NUMBER | Zeichenfolge von ein bis acht Ziffern |
| NUMBERS | Liste von NUMBER-Werten |
| NUTOKEN | Zeichenkette, die den Regeln für gültige Bezeichner entspricht, und mit einer Ziffer beginnt |
| NUTOKENS | Liste von NUTOKENS |
Beispiel 2.3 einer DTD für ein Dokument "Artikel" nach [ACM94]:
<!DOCTYPE article[
<!ELEMENT article - - (title,author+,affil,abstract,section+,acknowl)>
<!ATTLIST article status (final|draft) draft #REQUIRED>
<!ELEMENT title - - (#PCDATA)>
<!ELEMENT author - O (#PCDATA)>
<!ELEMENT abstract - O (#PCDATA)>
<!ELEMENT section - O ((title|body+)|(title,body*,subsectn+))>
<!ELEMENT subsectn - O (title,body+)>
<!ELEMENT body - O (figure,paragr)>
<!ELEMENT figure - O (picture,caption?)>
<!ATTLIST figure (label ID #IMPLIED)>
<!ELEMENT picture - O EMPTY>
<!ATTLIST picture sizex NMTOKEN "16cm"
sizey NMTOKEN #IMPLIED
file ENTITY #IMPLIED>
<!ELEMENT caption O O (#PCDATA)>
<!ENTITY file SYSTEM "/u/christoph/TEX/SGML/fig1.ps" NDATA >
<!ELEMENT paragr - O (#PCDATA)>
<!ATTLIST paragr reflabel IDREF #REQUIRED>
<!ELEMENT acknowl - O (#PCDATA>
]>
Beispiel 2.4 eines SGML-Dokumentes vom Typ Artikel nach [ACM94]
<article status="final">
<title>From Structured Documents to Novel Query Facilities</title>
<author>V. Christophides
<author>S. Abiteboul
...
<abstract>...
<section>
<title>Introduction</title>
...
<body><paragr>This paper...
</body></section>
<section>
<title>SGML preliminaries</title>
<body><paragr>...
</body></section>
...
</article>
Bei SGML spielt der Parser, bzw. Darsteller, welcher das SGML-Dokument verarbeitet eine wichtige Rolle, und es sollte bei der Erstellung einer DTD auf Eigenheiten des Parsers eingegangen werden, bzw. ein Parser benutzt werden, welcher die benötigten Anforderungen erfüllt. Beispiel.: Kapitel können automatisch oder manuell numeriert werden. Die Marken am Kapitelanfang hätten dann die Gestalt <section> bzw. <section number="3">. Die Angabe eines zusätzlichen Attributes wäre bei weniger leistungsfähigen Parsern/Darstellern nötig.
HTML wird durch eine spezielle DTD definiert. Die Entscheidung SGML als Grundlage für einen Netzdienst zu benutzen, war die Unabhängigkeit von SGML gegenüber spezieller Hardware oder Software und die Integrierbarkeit von Daten verschiedenen Typs. Außerdem sollte es möglich sein Hypertextdokumente zu erstellen, wofür sich SGML gut eignet. Zur Zeit sind die Versionen der HTML-DTD's 2.0 und 3.2 gebräuchlich. In HTML 3.0 wurden umfangreiche Möglichkeiten, unter anderem Formelsatz definiert. Allerdings wurden von existierenden HTML-Darstellern nie alle Möglichkeiten von HTML 3.0 realisiert. Einen Überblick über HTML 3 bietet das Buch "Die Sprache des Web - HTML 3" von R. Tolksdorf, welches auch in der MEDOC-Bibliothek verfügbar ist. Generell gilt, das existierende Systeme ( Web-Browser ) sich nicht an einen festen Standard halten. Verschiedene Web-Browser bieten verschiedene Erweiterungen der HTML-DTD an, wie zusätzliche Attribute und zusätzliche HTML-Tags. Die HTML-DTD weist einige Besonderheiten auf.
Beispiele für Elementdeklarationen
Bild:
<!ELEMENT IMG - O EMPTY
<!ATTLIST IMG
SRC %URI; #REQUIRED
ALT CDATA #IMPLIED
ALIGN (top|middle|bottom) #IMPLIED
ISMAP (ISMAP) #IMPLIED
%SDAPREF; "<Fig><?SDATrans Img: AttList>#AttVal(Alt)</Fig>"
>
<!-- <IMG> Image; icon, glyph or illustration ->
<!-- <IMG SRC="..."> Address of image object ->
<!-- IMG ALT="..."> Textual alternative ->
<!-- IMG ALIGN=...> Position relative to text ->
<!-- IMG ISMAP> Each pixel can be a link
Anker:
<!ELEMENT A - - %A.content -(A)>
<!ATTLIST A
HREF %URI #IMPLIED
NAME %linkName #IMPLIED
%linkExtraAttributes;
%SDAPREF; "<Anchor: #AttList>"
>
Linkkonzept im Vergleich zu SGML
Querverweise können naturgemäß nicht mehr über ID- und IDREFS-Attribute realisiert werden, da auch auf andere, Dokumente verwiesen werden soll. Die Links werden daher über eigene Elemente mit entsprechenden Attributen definiert und ihre Realisierung wird vollständig vom Browser vorgenommen. Durch die Benutzung eines eigenen Elementes, ist es möglich den Link mit einem Kontext zu versehen, was mit den ID- und IDREFS-Konstruktionen nicht möglich ist. ( <A HREF="externe Adresse">Kontext</A> )
Die Trennung von Layout und Inhalten ist in HTML nicht mehr konsequent. Viele Tags dienen der Festlegung eines bestimmten Layouts.
HyTime ist das Kürzel für "Hypermedia/Time-based Structuring Language", und ist in ISO 10744:1992 definiert. HyTime basiert auf SGML. Der Standard enthält viele verschiedene Aspekte bzgl. Querverweisen und ein großes Repertoire an Fähigkeiten für den Umgang mit Multimedia, unter anderem virtual time, scheduling, Synchronisation . Mit HyTime können Dokumente mit verschiedenen Datentypen durch Links verbunden werden.
Identifiziert werden die HyTime-Elemente durch ein spezielles HyTime-Attribut, welchem der Name des entsprechenden HyTime-Templates zugewiesen wird. Man kann Bezeichner für HyTime-Elemente frei wählen. Durch das HyTime-Attribut kann eine HyTime-fähige Applikation das Element als solches Erkennen und eine entsprechende Verarbeitung durchführen. Eine HyTime-Engine kann als SGML-Parser angesehen werden, welcher die Aktionen, die die HyTime-Attribute erfordern verstehen und veranlassen kann.
Eine bestehende DTD kann durch Hinzunahme der HyTime-Deklarationen die Möglichkeiten von HyTime nutzen. Eine Konvertierung ist nicht erforderlich.
HyTime erweitert das klassische Modell der bibliographischen Verweise zu einem computergestützten Modell "Integrated Open Hypermedia (IOH)". Dieses Modell erlaubt es verschiedene Datentypen aus mehreren verschiedenen Quellen durch Links miteinander zu verbinden. Die Besonderheiten von HyTime liegen in den umfangreichen Möglichkeiten Linkaddressen zu formulieren. HyTime kann man jedes Objekt referenzieren. Handelt es sich um ein strukturiertes Objekt, wie z.B. ein SGML-Dokument, dann können Positionen in der Struktur des Objektes benutzt werden um die Ankerpunkte der Links zu beschreiben. Ist das Dokument unstrukturiert wie z.B. reiner ASCII-Text, dann können Anker mit Hilfe von Byteposition, eindeutigen Bezeichnern oder Suchmustern im Dokument festgelegt werden. Für nicht-Textdokumente kann die Addressierung über Bitmap Suchmuster oder einer Angabe von Koordinaten, welche die Applikation die mit dem Objekt arbeitet benutzt, erfolgen. Für jedes Objekt ist dabei eine Definition mehrerer verschiedener Koordinatensysteme möglich. Wie in Bildern, können auch Addressen in Musikstücken ( MIDI ) und anderen Audiodateien festgelegt werden.
In HyTime unterscheidet man zwischen Links und Location. Ein Link ist eine Beziehung zwischen zwei oder mehreren Locations. Eine Location ist die Adresse eines potentiellen Ankerpunktes, welcher das tatsächliche Ende des Links darstellt.

Abbildung 9: HyTime Linkkonzept ( aus [BEHAHE96] )
Durch diese zunächst etwas kompliziert erscheinende Konstruktion
ist eine Veränderung/Aktualisierung der Links weniger aufwendig.
In SGML werden Querverweise mit Hilfe von ID-Attributen und Referenzen
auf diese durch IDREF- und IDREFS-Attribute realisiert. Allerdings lassen
sich damit nur Links innerhalb eines einzigen Dokumentes realisieren.
Obwohl der HyTime-Standard auf SGML basiert übertrifft er die Begrenzungen
der SGML-Links und erweitert sie stark.
HyTime definiert zwei Link-Konstrukte. Contextual Link ("clink") und independent
Link ("ilink"). Die Locations lassen sich in HyTime auf vielfältige
Weise angeben. Oft werden diese als Sequenz sich schrittweise verfeinernder
Adressen angegeben ( "location ladders" )
Herkömmliche SGML-Referenz:
... <xref idref="tab21">...
<tbl id="tab21">
<tbltitle>Population...</tbltitle>
<body>...
Der kontextbezogene Link ist der einfachere der HyTime-Linkkonstrukte. Einer seiner Anker ( der "Kontext" ) ist Bestandteil des Dokumentes, an der Stelle, bei der sich die Linkauszeichnung befindet. Die anderen Endpunkte können sich im gleichen oder in anderen Dokumenten befinden. Durch ein IDREF-Attribut wird ein Element referenziert, welches eine HyTime-Adressierung benutzt. Das clink-Konstrukt beschreibt klassische Querverweise.
Der independent Link erlaubt es die Linkdaten extern zu speichern. Die Daten sind getrennt von den Dokumenten, welche mit dem Linkmarkup ausgezeichnet sind. Damit ist es möglich Änderungen an den Linkdaten vorzunehmen, ohne die Dokumente zu verändern, auf die sich der Link bezieht.
Die üblichen Vorteile sind schneller Zugriff, einfaches Kopieren, universelle Einsetzbarkeit. Eine Online-Präsentation, bzw. ein Onlineangebot ermöglicht größtmögliche Aktualität der angebotenen Informationen. Als bei Computersystemen generell nachteilig gegenüber herkömmlichen, papiergebundenen Angeboten ist, daß der Zugriff auf die Dokumente ohne technische Hilfsmittel nicht möglich ist. Des weiteren eignet sich ein Computerbildschirm nicht zum längeren Lesen von Dokumenten. Der "Transport" der Dokumente erfolgt mit Hilfe von Speichermedien ( Diskette, CD, Laptop ) oder der Nutzung von Computernetzwerken.
In einem elektronischen Informationssystems bieten sich erweiterte Möglichkeiten der Dokumentverwaltung. Es ist zum Beispiel möglich die Dokumente über Computernetze zu verbreiten. Eine umfassende statistische Auswertung der Dokumente ist möglich. Versionenmanagement wird einfach erreicht. In Zukunft wird es neben dem herkömmlichen Dokument "Buch" auch Dokumente mit ständiger Pflege und Aktualisierung des Inhaltes geben. Als erste Anfänge dieser Dokumente sind die regelmäßig aktualisierten FAQ-Sammlungen mancher Internet-Newsgruppen zu nennen. Diese werden meist von den Moderatoren dieser Newsgruppen herausgegeben, und spiegeln die Ergebnisse der Diskussionen in der jeweiligen Newsgruppe über längere Zeiträume wieder. Ein weiteres Beispiel wäre: Ein Firma führt ein größeres Projekt durch. Die Mitarbeiter dieses Projektes stammen aus verschiedenen Niederlassungen dieser Firma. Die Mitarbeiter legen ihre bereits fertiggestellten Ergebnisse in einem elektronischem Informationssystem ab ( z.B. SGML-Datenbank ). Während der Dauer des Projektes ist es für alle mitarbeitenden Personen einfach möglich Arbeitsergebnisse auszutauschen. Der Projektleiter kann sich jederzeit über den aktuellen Stand der abgeschlossenen Arbeiten informieren. Die Erstellung von Zwischenberichten ist ohne größeren Aufwand möglich. Schließlich hat man durch die Reduzierung des Kommunikationsaufwandes mehr Zeit für konkrete Aufgaben. Es muß allerdings vorausgesetzt werden, daß eine zweckmäßige Organisation der Daten vorliegt, d.h. es sollte eine hierarchische Struktur vorliegen, außerdem sollten Änderungen an der Datenstruktur mit zumutbarem Aufwand möglich sein. Standardisierte Dokumentenaustauschformate sollten verwendet werden. Die eben genannten Dinge lassen sich mit einer SGML-Datenbank realisieren. Elektronische Systeme können in gewissen Grenzen ( je nach "Intelligenz" des Systems ) die Integrität der erzeugten Daten sichern und überwachen, z.B. die Überprüfung von Hypertextlinks.
Dokumentverwaltung
Zentrale Verwaltung ermöglicht einfach Multiautorprojekte, durch Computernetze können Autoren an beliebigen Orten arbeiten. Die Dokumente sind immer auf dem aktuellsten Stand. Die Dokumente müssen dazu in handhabbare Teile zerlegt werden. Vom Informationssystem können auch Hypertextfähigkeiten bereitgestellt werden, d.h. die Autoren können in ihren Dokumenten Beziehungen zu anderen Dokumenten herstellen und damit ihren inhaltlichen Bezügen auf andere Dokumente eine neue Qualität verleihen.
Bei Textdokumenten hat man keine starre Struktur vorliegen, Änderungen an der Struktur der Dokumente werden oft gemacht und sollten immer einfach möglich sein. Objektorientierte Datenbanken erlauben es auf einfache Weise Daten verschiedener Typen zu beschreiben und zu speichern. Objektorientierte Datenbanken ermöglichen die Speicherung von hierarchischen Datenstrukturen. Objekte können andere Objekte des gleichen, oder eines verschiedenen Typs enthalten und können selbst in anderen Objekten enthalten sein. Die Fähigkeit hierarchische Strukturen und verschiedene Datentypen innerhalb einer Struktur zu speichern, ist genau richtig für die Speicherung von SGML-Dokumenten. Hierarchische Speicherung allein reicht aber für SGML-Dokumente nicht aus. Die ursprüngliche Ordnung der Daten muß erhalten bleiben. Mit objektorientierten Datenbanken ist diese Ordnung aber, im Gegensatz zum relationalen Modell, leicht herzustellen. ( z.B. Verwendung von Listen ) Mit dem relationalen Modell lassen sich die vielfältigen Beziehungen innerhalb der SGML-Dokumente nicht vernünftig darstellen. Zusätzlich wäre der Zugriff auf die Daten im relationalen System mit einer Vielzahl von Join-Operationen verbunden.
Transfer der SGML-Dokumente in die Datenbank
Bevor ein SGML-Dokument in die Datenbank geladen werden kann müssen die Klassendefinitionen erstellt werden. Für jedes Element der DTD wird eine eigene Klasse erstellt. Eine Möglichkeit des Ladens eines Dokumentes in die Datenbank wird durch Abbildung 10 veranschaulicht. Das SGML-Front-End teilt das Dokument in seine Bestandteile auf, erzeugt alle benötigten Objekte und legt diese in der Datenbank ab. Es werden Objekte mit verschiedenen Datentypen erstellt, auch multimediale Daten können mit den Objekten abgespeichert werden. Die in Abbildung 10 gezeigte Lösung ist recht komfortabel, insbesondere der mitgelieferte Volltextindex stellt eine nicht zu unterschätzende Aufwertung des Systems dar.

Abbildung 10: Objektorientierte Datenbank mit SGML Front-End, aus [TRWA95]
Ein bedeutender Faktor bei der Implementierung einer SGML-Datenbank
ist die Festlegung des Grades der Granularität, mit welchem die Informationen
in der Datenbank abgelegt werden sollen. Eine Einheit ist typischerweise
ein Kapitel oder ein Teil, es ist jedoch auch möglich, daß jeder
Absatz eine Einheit bildet. Wählt man die Granularität zu groß,
z.B. Teil, dann muß der Autor bei der Änderung an einem Kapitel
einen ganzen Teil aus der Datenbank laden, Autoren die an anderen Kapiteln
dieses Teils arbeiten wollen, erhalten keinen Zugriff. Wählt man die
Granularität zu klein, z.B. Absatz: will der Autor größere
Änderungen an einem Kapitel vornehmen, muß er jeden Absatz einzeln
modifizieren. Die eben genannten Probleme lassen sich durch eine hierarchische
Speicherungsstruktur lösen. Eine geeignete Benutzeroberfläche
kann den Zugriff auf die einzelnen Absätze durchführen. Der Benutzer
arbeitet dabei auf einer höheren Ebene, z.B. Kapitelebene. Mit der
letzterenLösung ist eine kleine Granularität vorteilhaft.
Den Grad der Granularität zu bestimmen wird davon beeinflußt,
wie die Daten strukturiert sind, und welchem Zweck sie dienen sollen.
Manchmal definiert sich der Grad der Granularität auch selbst. Ein
gebräuchlicher Weg ist ein Dokument in Kapitel oder Unterkapitel aufzuteilen.
Das ist der Grad, mit welchem Autoren oft arbeiten. In vielen Fällen,
z.B. wenn ein Buch mehrere Autoren hat, wird ein Kapitel von einer einzelnen
Person erstellt. Bei Setzung der Granularität auf diesen Grad, repräsentiert
die Datenbank den natürlichen Umgang der Autoren mit dem Dokument.
Es sind auch die technischen Faktoren bei der Festlegung der Granularität
zu berücksichtigen. Für jedes Objekt ist ein gewisser Datenbankoverhead
an Daten und Datenstrukturen vorhanden. Bei Systemen mit Granularität
auf Absatzebene überschreitet die Größe des Overheads bereits
die Größe des Inhaltes. [TRWA95] Der Speicherplatzbedarf
ist, bei der Festlegung der Granularität gegen die Zugriffskosten
abzuwägen.
Im folgenden Beispiel aus [ACM94] wird gezeigt,
wie SGML-Dokumente in einer objektorientierten Datenbank, konkret O2, repräsentiert
werden können und wie man Dokumente in Datenbankinstanzen übertragen
kann. Für den Einsatz von O2 spricht zum einen die Abfragesprache
OQL , und das gut entwickelte Typensystem. Die hierarchische Struktur eines
SGML-Dokumentes kann durch die vorhandenen Datentypen von O2 repräsentiert
werden. Das Datenmodell von O2 , besteht aus selbst zu definierenden Objektklassen
und vorgefertigten Typen. Insbesondere Aggregation und Listen lassen sich
gut für die Beschreibung der Dokumentstruktur einsetzen. Multimediatypen
lassen sich im allgemeinen einfach in objektorientierte Datenbanken eingliedern,
in O2 ist für Bilder schon der Datentyp "Image" vorhanden. Querverweise
zwischen logischen Einheiten lassen sich einfach durch Nutzung der Objektidentität
realisieren. Nicht zuletzt ist Objekt-Sharing nützlich bei der Modifizierung
von Dokumenten, was vor allem die Erstellung von Dokumenten unterstützt.
Allerdings gibt es für die Übertragung von speziellen SGML-Konstrukten,
wie Verbindungssymbolen ( connectors ) und Vorkommenssymbolen ( occurence
Indicator ) in O2 und anderen objektorientierten Datenbanken keine geeigneten
Datentypen. Es müssen daher andere Lösungen benutzt werden.
Geordnete Tupel: Die Ordnung von Elementen innerhalb eines Tupels ist in SGML wesentlich. Die Übertragung solcher geordneter Tupel in Datenstrukturen des Datenbanksystems erfordert Kompromisse. Eine Möglichkeit ist, in ein Objekt ein zusätzliches Attribut einzufügen, in welchem die Reihenfolge der Elemente gespeichert wird. Diese Lösung ist aber nachteilig für die Formulierung von Anfragen.
Vereinigung von Typen: Ein Elementtyp kann in SGML als alternative Struktur vereinbart werden. Eine Vereinigung von Typen ist dafür die geeignete Lösung. Der Typ "Union" gehört nicht unmittelbar zu O2 und muß daher selbst vereinbart werden. Ein Tag innerhalb des Uniontyps gibt an, welcher der alternativen Typen benutzt werden soll.
Beispiel 4.1: O2 Klassen für Dokumente vom Typ Artikel nach [ACM94]
class Article public type tuple(title: Title, authors: list(Author), affil: Affil,
abstract: Abstract, sections: list(Section),
acknowl: Acknowl, private status: string)
constraint: title != nil, authors != list(), abstract != nil,
sections != list(), status in set("final","draft")
class Title inherit Text
class Author inherit Text
class Affil inherit Text
class Abstract inherit Text
class Section public type union(a1: tuple(title: Title, bodies: list(Body)),
a2: tuple(title: Title, bodies: list(Body),
subsectns: list(Subsectn)))
constraint: (a1.title != nil, a1.bodies != list())
|(a2.title != nil, a2.subsectns != list())
class Subsectn public type tuple (title: Title, bodies: list(Body))
constraint: title != nil, bodies != list()
class Body public type union(figure: Figure, paragr: Paragr)
constraint: figure != nil | paragr != nil
class Figure public type tuple(picture: Picture, caption: Caption,
label: list(Object))
constraint: picture != nil
class Picture inherit Bitmap
class Caption inherit Text
class Paragr inherit Text
type tuple(private reflabel: Object)
constraint: reflabel != nil
class Acknowl inherit Text
name Articles: list(Article)
Ein Problem besteht darin aus einem SGML-Dokument eine Datenbankrepräsentation
zu erzeugen. Die DTD muß dazu in ein O2-Schema überführt
werden, und die Dokumentinstanzen müssen in die entsprechenden Objekte
abgespeichert werden. Jedes in der DTD definierte SGML-Element wird als
eine Klasse eines Typs, mit einigen Integritätsbedingungen und Standardmethoden
( z.B.: Lese- und Schreibmethoden für jedes Attribut ) erzeugt. Das
Beispiel 4.1 zeigt die O2-Repräsentation der aus Beispiel 2.3 entnommenen
DTD. Ein Basistyp von SGML wird durch eine O2 Klasse mit entsprechenden
Datentypen repräsentiert ( Text, Bitmap ). Die O2-Tupel werden als
geordnet angesehen. Die Verbindungen ("|") zwischen den Elementen werden
durch Union-Typen ausgedrückt. Für SGML-Elemente ohne direkte
Benennung ( ein expliziter Bezeichner fehlt ) die durch verschachtelte
runde Klammern definiert sind ( z.B. (title,body+) in Beispiel 2.3, Definition
von "section" ), werden vom System eigene Namen erzeugt. ( z.B. a1 in der
Klasse "section" ) Die mit "+" oder "*" gekennzeichneten Elemente werden
als Listen dargestellt. ( siehe Attribut "author" in Klasse "Article")
Integritätsbedingungen müssen eingeführt werden, um die
verschiedenen Suffixe ( "+","*" : Angaben über die Anzahl des Vorkommens
der Elemente ) nachzubilden ( Wert ist erforderlich, Wert muß mindestens
einmal vorkommen, usw. )
Die Flexibilisierung des Zugriffs auf die Daten, die eine Repräsentation
von SGML-Dokumenten in einer objektorientierten Datenbank bietet, werden
dabei durch einen erhöhten Speicherbedarf erkauft.
Ohne eine objektorientierte Datenbank werden Abfragen in SGML-Dokumenten
üblicherweise in der Art von Information Retrieval Systems (IRS) durchgeführt.
IRS bieten zwei wesentliche Fähigkeiten, die in objektorientierten
Datenbanken fehlen. Dazu gehört ein umfangreiches pattern matching
basierend auf einem Volltextindex und als Wesentliches: der Benutzer braucht
die Struktur des Dokumentes für die Formulierung seiner Anfragen nicht
zu kennen. Natürlich möchte man auf diese Fähigkeiten bei
einem objektorientiertem Datenbanksystem nicht verzichten.
Im folgenden wird gezeigt, wie diese beiden Fähigkeiten in O2 nachgebildet
werden.
O2SQL ist definiert über einer Menge von Grundabfragen und der
Möglichkeit neue Abfragen durch Komposition zu erstellen. Um die IRS-Fähigkeiten
in das bestehende System zu bringen werden neue Grundabfragen in das Modell
eingebracht.
Die folgende Abfrage führt das Prädikat "contains" ein, welches
Pattern-Matching erlaubt.
Q1: Finde den Titel und den ersten Autor der Artikel die im Titel die Worte "SGML" und "OODBMS" enthalten.
Select tuple(t: a.title, f: first(a.authors))
from a in Articles, s in a.sections
where s.title contains ("SGML" and "OODBMS")
Das "contains"-Prädikat erlaubt einen String mit einem Zeichenmuster (Pattern), oder einer booleschen Kombination von Zeichenmustern zu vergleichen. Außerdem wurde neben anderen neuen Prädikaten auch das "near"-Prädikat implementiert, welches erlaubt, den Abstand zweier gefundener Zeichenmuster einzugrenzen ( Abstand als bestimmte Anzahl von Buchstaben oder Worten ).
Verwendung von Uniontypen
Die Einführung von Uniontypen erfordert einige größere
Änderungen an der Typprüfung von O2SQL Anfragen und auch Änderungen
bei den O2SQL Iteratoren ( select-from-where, exists, etc) . Wenn zum Beispiel
eine "collection" aufgebaut wird, wird überprüft, ob die Elemente
einen gemeinsamen Supertyp haben.
O2SQL zwingt zu Typrestriktionen. Mit der Einführung des Uniontyps
müssen auch Typregeln festgelegt werden. Es folgen nun die zwei Hauptregeln
:
Regel 1 muß nur selten benutzt werden und die zu erwartende Vervielfachung
durch Regel 2 läßt sich durch Hinzufügen von Semantikregeln
im O2SQL Typensystem unter Kontrolle bringen.
Das folgende Beispiel zeigt, wie in O2SQL die Auswertung von Iteratoren
modifiziert wurde, um Uniontypen zu verarbeiten.
Q2: Finde alle Unterkapitel der Artikel, die "complex object" enthalten.
select ss
from a in Articles, s in a.sections,
ss in s.subsectns
where text(ss) contains("complex object")
Im Gegensatz zu Q1 wird die "contains"-Operation nicht über einzelnen Datenobjekten, sondern über komplexeren logischen Objekten ( hier Unterkapitel ) durchgeführt. Durch Verwendung des Operators "text", welcher vom System bereitgestellt wird, läßt sich die "contains"-Operation dennoch anwenden. Im Schema des Beispiels 4.1 haben Kapitel (sections) einen Uniontyp. Ein Kapitel welches mit "a1" bezeichnet ist, steht für ein Tupel mit den Attributen "title" und "body" und ein Kapitel "a2" für ein Tupel mit "title", "bodies" und "subsectns". In der Anfrage Q2 erstreckt sich die Variable "ss" über Unterkapitel von Kapiteln, die mit "a2" bezeichnet wurden. Zwei Bemerkungen sind dazu notwendig. Erstens: In der Abfrage wird bei der Definition der Variable "ss" in der From-Klausel, der Bezeichner "a2" weggelassen. Diese syntaktische Besonderheit ist notwendig, da der Benutzer im allgemeinen die Bezeichnungen in den Uniontypen nicht kennt. Zweitens: Eine Nichtbehandlung der Kapitel, die nicht mit "a2" bezeichnet sind, ist nicht erwünscht. ( Die Kapitel ohne Unterkapitel sollen bei der Abfrage nicht vergessen werden ).
Um dieses Problem zu bewältigen wird der Begriff des "implicit selectors" eingeführt. Jede Operation auf einer Variable, die sich über Uniontypen erstreckt erfordert eine "bedingungslose Auswahl", d.h. , daß von dem Uniontyp automatisch der vorhandene ( mit Werten belegte ) Typ geliefert wird. In Q2 ist die "implicit selection" "s.a2". Dieser Mechanismus funktioniert allerdings nur für Variablen und nicht für konkrete Instanzen. Als Beispiel: angenommen es gibt einen Namen "my_section", der instanziiert wird durch ein Kapitel bezeichnet mit "a1". In diesem Fall liefert die Abfrage "my_sections.subsectns" zur Laufzeit einen Typenkonflikt.
Nun zurück zu den syntaktischen Besonderheiten eines etwas komplizierteren Beispiels. Angenommen, man ist anstelle der Unterkapitel an den Inhalten ( bodies ) des Artikels interessiert. Die From-Klausel erhält folgende Gestalt: from a in Articles, s in a.sections, b in s.bodies . Die Variable "b" erstreckt sich dabei über die Vereiningung von "s.a1.bodies" und "s.a2.bodies" und zwei "implicit selectors" müssen verwendet werden, um Ausführungsfehler zu vermeiden. In diesem Fall sind beide Attribute "bodies" vom gleichen Typ, das kann aber nicht immer vorausgesetzt werden. Wenn das nicht der Fall sein sollte wird vom System ein bezeichneter Uniontyp generiert.
Um die Dokumente Abzufragen ohne genaue Kenntnisse über ihre Struktur zu besitzen werden zwei neue Konstrukte eingeführt: PATH und ATT. Einen Wert aus dem vorher besprochenem wird durch einen Pfad durch komplexe Objekte ( Tupel, Listen ) und einem Attributnamen ( eines Tupels oder einer bezeichneten Union ) repräsentiert. Zum Beispiel ist ".sections[0].subsectns[0]" ein Pfad, der das Attribut "sections" vom Typ Liste, dann das erste Kapitel, dann das Attribut "subsectns" dieses Kapitels und schließlich das erste Unterkapitel bezeichnet. Diese Pfade können wie normale Daten abgefragt werden.
Wie alle Typen, die in O2SQL manipuliert wurden, haben "PATH" und "ATT" ihre eigenen Variablen und Standardabfragen. Um Variablen nach ihrer Art ( normale Daten, PATH, ATT ) zu unterscheiden werden PATH-Variablen mit "PATH_" und ATT-Variablen mit "ATT_" begonnen. In der nächsten Abfrage ist "my_article" ein Persistent-Root-Objekt, welches einen Artikel darstellt.
Q3: Finde alle Titel in "my_article".
select t
from my_article PATH_p.title(t)
Als Ergebnis erhält man eine Menge von Titeln, die von verschiedenen
Pfaden der Artikelstruktur aus erreicht werden können. ( Haupttitel,
Titel eines Kapitels, Titel eines Unterkapitels ... )
Die Unterabfrage "my_article PATH_p.title(t)" ist eine neue Standardabfrage.
Es handelt sich um einen Pfadausdruck mit Variablen ( im Beispiel "PATH_p"
und "t" ), dessen Semantik sich von herkömmlichen Pfadausdrücken
unterscheidet. Die eben genannten Abfragen liefern eine Menge von Tupeln
mit einem Attribut je Variable zurück. Im Beispiel werden Tupel mit
zwei Attributen zurückgeliefert : "t" und "PATH_p"
Es bleibt noch einiges anzumerken:
Für ein weiteres Beispiel der Benutzung von Abfragen mit Pfaden ohne die genaue Struktur des Dokumentes zu kennen, sei "my_old_article" der Name einer älteren Version von "my_article". Dann läßt sich die folgende Abfrage durchführen:
Q4: Zeige die strukturellen Unterschiede der zwei Versionen von "my_article"
my_article PATH_p - my_old_article PATH_p
Der linke Teil der Differenzbildung liefert eine Menge von Pfaden beginnend bei "my_article" ( beim rechten Teil analog, aber beginnend bei "my_old_article" ). Die Differenzoperation liefert die Pfade zurück, die in der neuen Version von "my_article" enthalten sind und nicht in der Alten. Ergänzende Bedingungen in der Datenstruktur des Dokumentensystems könnten so eine Erkennung von Aktualisierungen oder Umstellungen von Textobjekten im inneren der Dokumentstruktur ermöglichen.
Im der nächsten Abfrage werden auch Attribute verwendet.
Q5: Finde die Attribute, die in "my_article" definiert sind, und deren Belegung den Wert "final" enthält.
select name(ATT_a)
from ma_article PATH_p.ATT_a(val)
where val contains ("final")
In diesem Beispiel erstreckt sich der Bereich der Variablen "val" über Daten, die von "my_article" aus über einen Pfad, hier "PATH_p" erreicht werden können ( auch leerer Pfad ist möglich ), bis zum Attribut, das von ATT_a geliefert wird. Entsprechend dem Initialtyp von "val" wird die Vereinigung aller möglichen Typen die in "myarticle" vorkommen gefunden. Die Unterabfrage " val contains ("final") " benutzt die "implicit selection" "val.a" wobei "a: string" ein Attribut vom Typ String im entsprechenden Uniontyp ist. O2SQL ordnet "val" den Typ string zu. Die zurückgelieferten Attribute sind die, deren Wert "final" enthält. Mit dieser Möglichkeit ist eine weitere Qualitätsstufe bei Abfragen auf objektorientierten Datenbanken realisiert. Die Funktion "name" liefert eine Zeichenkette zurück, hier den Namen des Attributes.
Abfragen über Attributen bezüglich ihrer Position
In diesem Abschnitt wird das Problem der geordneten Tupel besprochen. In SGML-Dokumenten werden geordnete Tupel für die Repräsentation der Daten benutzt. Die Eigenschaft des Geordnetseins läßt die Betrachtung eines geordneten Tupels als heterogene Liste zu. Als Beispiel nehmen wir an, daß unsere Datenbank Briefe enthält. Diese Briefe besitzen eine Einleitung, die unter anderem die Empfänger- ( Attribut "to" ) und die Absenderadresse ( Attribut "from" ) enthält. Eine Reihenfolge beider Attribute ist von der SGML-Deklaration her nicht vorgesehen ( Verwendung des "&" Verbinders ). Damit läßt sich folgende Abfrage konstruieren:
Q6: Finde die Briefe, in denen in der Einleitung der Absender vor dem Empfänger steht.
select letter
from letter in Letters, letter.preamble[i].to,
letter.preamble[j].from
where i < j
Bei dieser Abfrage muß man beachten, das bei den Tupeln ( to:
string ; from: string ; ... ), welche die Einleitung eines Briefes als
eine Liste von Elementen, die zu einem Uniontyp [( to: string + from:string
+ ... )] gehören, repräsentieren, jeder der Typen durch den Attributsnamen
des Originaltupels bezeichnet ist.
Eine ausführlichere Erläuterung: "letter.preamble[i].to" und
"letter.preamble[j].from" bearbeiten immer den gleichen Brief ( "letter"
) ( erster Teil der From-Klausel ) , "i" in "letter.preamble[i].to" gibt
die Position des Attributes "to" im entsprechenden Tupel an, "j" in "letter.preamble[j].from"
gibt die entsprechende Position des Attributes "from" im entsprechenden
Tupel an.
Also definiert die from-Klausel drei Datenvariablen: "letter" der alle Briefe umfaßt, sowie "i" und "j" die über die Positionen der Marker "from" und "to" in den entsprechenden Briefen reichen. Die where-Klausel wird benutzt, um die gewünschten Tripel ( Brief, i, j ) zu selektieren, und die select-Klausel gibt die entsprechenden Briefe zurück.
Generell ist die automatische Erzeugung von Objektklassen aufgrund der großen Menge von Dokumenten notwendig. Da man aber in einer Datenbank Dokumente mit verschiedenen DTD's aufbewahren kann, kommt es unter Umständen zu Schwierigkeiten. Zum Beispiel ist es denkbar, daß in unterschiedlichen DTD's unterschiedliche Bezeichnungen für die Einheit "Kapitel" verwendet werden, was sich nachteilig für die Formulierung von Abfragen auswirkt. Eine einheitliche DTD läßt sich aber in einem größerem bzw. universellen System nicht direkt bzw. nur unter größeren Umständen realisieren. Denkbar wäre eine Übersetzung der SGML-Dokumente auf eine im Datenbanksystem benutzte DTD. Diese Übertragung läßt sich aber im allgemeinen nicht vollständig automatisieren. Außerdem können spezielle Konstruktionen einer DTD nicht immer 100% sinnentsprechend auf eine andere DTD übertragen werden.
SGML läßt sich universell für die Beschreibung von Dokumenten einsetzen. Mit SGML erstellte Dokumente eignen sich für einen Dokumentenaustausch. Bei der Trennung von Inhalt und Layout überwiegen die Vorteile gegenüber einem konventionellen System. Der Hauptvorteil ist die Möglichkeit ein Dokument für verschiedene Medien aufzubereiten. Ein weiterer Vorteil besteht darin, verschiedene Sichten auf ein Dokument für verschiedene Zielgruppen zu erstellen. Mit SGML-Dokumenten lassen sich die Möglichkeiten der elektronischen Datenverarbeitung besser als bisher ausnutzen. Durch die Verwendung von speziellen SGML-Editoren kann die Erstellung von Dokumenten unterstützt werden. Mit SGML lassen sich Dokumentenmanagementsysteme realisieren. Die Errichtung einer digitalen Bibliothek, welche auch vom Internet aus recherchiert werden kann ist mit SGML-Unterstützung möglich. Der SGML-Standard erlangt immer mehr an Bedeutung, vor allem, weil durch die stark wachsende Dokumentenmenge Werkzeuge zu einer effektiven Bearbeitung gebraucht werden. Für die Abspeicherung von SGML-Dokumenten bieten sich objektorientierte Datenbanken an. Sie bieten alle wesentlichen Möglichkeiten, die ein effektives Arbeiten mit SGML-Dokumenten erfordert. Information Retrieval Systeme auf SGML-Basis stehen noch am Anfang ihrer Entwicklung. Die Umsetzung typischer IRS-Anfragen auf Objektorientierte Datenbanken bieten neue Möglichkeiten, wie z.B. der gezielten Suche in Überschriften oder einzelnen Kapiteln.
ACM94 Christophides, V.; Abiteboul, S.; Cluet, S.; Scholl, M.: From structured documents to novel query facilities. Proc. ACM SIGMOD conf., 1994 , [R 9315]
BAN94 Böhm, K; Aberer, K.; Neuhold, E. : Administering structured documents in digital libraries. Proc. Workshop on Digital Libraries 1994 , ( LNCS 916 ), [K 8373]
BEHAHE96 Bergström, Peter; Haitto, Hasse; Helander, Erik u.a. : Quick Guide to HyTime Basics, Technical Report 1 from the HyTime Working Group, Swedish SGML User's Group 1996
BRYA93 Bryan, Martin : Standards for text and hypermedia processing. aus Information Services & Use 13, IOS Press 1993
COJA96 Colby, Martin; Jackson, David S. : Special Edition Using SGML QUE Corporation, 1996
SZ95 Szillat, Horst : SGML Eine Praktische Einführung. 1. Auflage, International Thomson Publishing, Bonn 1995 , [R 7468]
TO95 Tolksdorf, Robert : Die Sprache des Web - HTML 3 . 2. Auflage, dpunkt-Verlag
TRWA95 Travis B., Waldt D. : The SGML Implementation Guide. Springer Berlin 1995 , [R 8272]